[論文レビュー] Self-Ensembling with GAN-based Data Augmentation for Domain Adaptation in Semantic Segmentation
本論文は、GANベースの、ターゲットドメインにガイドされた、サイクルフリーなデータ拡張(TGCF-DA)と自己アンサンブルを組み合わせることでドメインシフトを低減する、セマンティックセグメンテーションのための新規なドメイン適応フレームワークを提案する。ターゲットドメインからの意味的に整合性のあるスタイル変換画像を生成し、教師ネットワークからの疑似ラベルを活用することで、GTA5→CityscapesおよびSYNTHIA→Cityscapesベンチマークで最先端の性能を達成し、既存の手法を上回る。
Deep learning-based semantic segmentation methods have an intrinsic limitation that training a model requires a large amount of data with pixel-level annotations. To address this challenging issue, many researchers give attention to unsupervised domain adaptation for semantic segmentation. Unsupervised domain adaptation seeks to adapt the model trained on the source domain to the target domain. In this paper, we introduce a self-ensembling technique, one of the successful methods for domain adaptation in classification. However, applying self-ensembling to semantic segmentation is very difficult because heavily-tuned manual data augmentation used in self-ensembling is not useful to reduce the large domain gap in the semantic segmentation. To overcome this limitation, we propose a novel framework consisting of two components, which are complementary to each other. First, we present a data augmentation method based on Generative Adversarial Networks (GANs), which is computationally efficient and effective to facilitate domain alignment. Given those augmented images, we apply self-ensembling to enhance the performance of the segmentation network on the target domain. The proposed method outperforms state-of-the-art semantic segmentation methods on unsupervised domain adaptation benchmarks.
研究の動機と目的
- 合成(ソース)ドメインから現実世界(ターゲット)ドメインにセマンティックセグメンテーションを適用する際のドメインシフトの課題に対処すること。
- 自己アンサンブルにおけるデータ拡張の手動的手法が引き起こす空間的不整合の問題を克服すること。
- ターゲットドメインのスタイルを効果的に転送しながら意味的整合性を保持する、効率的でサイクルフリーなGANベースのデータ拡張法を開発すること。
- 提案された拡張法と自己アンサンブルを統合し、ターゲットドメインにおけるモデルの一般化性能を向上させること。
- セマンティックセグメンテーションの標準的な教師なしドメイン適応ベンチマークで最先端の性能を達成すること。
提案手法
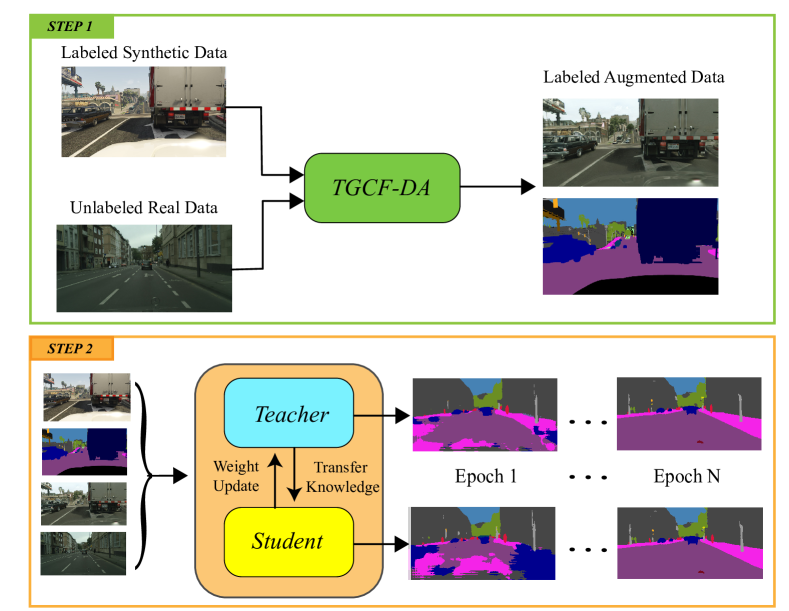
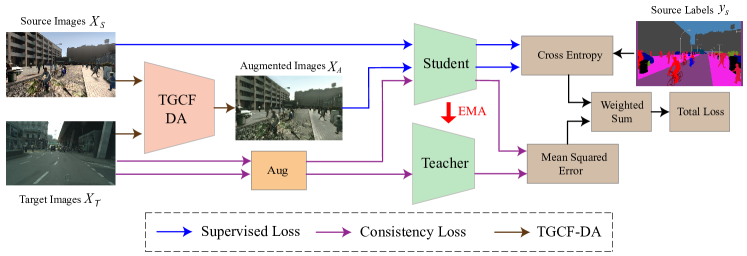
- ターゲットドメインの画像からスタイルを転送しながらも意味的コンテンツを保持する、GANベースの拡張法である、ターゲットガイドドでサイクルフリーなデータ拡張(TGCF-DA)を提案する。
- 生成器に意味的整合性損失を適用し、拡張画像におけるグローバルおよびローカルな構造的保存を制約する。
- 生成器をターゲットドメインのスタイル特徴量で条件づけることで、サイクル整合性を必要とせず、現実的でドメインに整合した拡張を実現する。
- 教師-生徒アーキテクチャを用いた自己アンサンブルフレームワークを実装し、教師の予測結果を学生のための疑似ラベルとして利用する。
- トレーニング中に徐々に整合性損失の影響を高めるために、段階的加重を施したラムプアップ整合性損失を適用する。
- 指数的移動平均(EMA)を用い、衰減を制御することで、教師ネットワークの予測を時間的に安定化させる。
実験結果
リサーチクエスチョン
- RQ1サイクル整合性に依存せずに、GANベースのターゲットガイドドなデータ拡張が、セマンティックセグメンテーションにおけるドメインシフトを低減できるか。
- RQ2標準的なデータ拡張と比較して、GAN拡張データを用いた自己アンサンブルは、ドメイン適応性能をどのように向上させるか。
- RQ3提案されたサイクルフリーで意味的整合性のある拡張は、セグメンテーションにおける自己アンサンブルの空間的不整合問題を緩和できるか。
- RQ4EMAの衰減率や整合性損失のラムプアップ係数といったハイパーパrameterが、モデルの収束と性能に与える影響は何か。
- RQ5ベースラインの自己アンサンブルと比較して、本手法は特に少数クラスにおいて、クラスごとのIoUをどの程度向上させるか。
主な発見
- 提案手法は、GTA5→CityscapesおよびSYNTHIA→Cityscapesベンチマークで最先端の性能を達成し、既存の最先端手法を上回った。
- GTA5→Cityscapesでは、自己アンサンブルを適用した場合、ベースラインのTGCF-DA(41.3)から顕著に向上し、平均IoUが42.5に達した。
- SYNTHIA→Cityscapesでは、平均IoUが38.5に達し、両ベンチマークで一貫した向上を示した。
- クラスごとのIoU分析から、主なクラス(例:'road')では大きな向上が見られた一方、少数クラス(例:'bus')では改善が限定的であった。これは、疑似ラベルの品質にクラス不均衡の影響があることを示唆している。
- ハイパーパrameterのアブレーション実験から、後期のトレーニングでEMAの衰減率を0.999に設定し、ラムプアップ係数δ₀ = 30とすることで最適な性能が得られた。
- 可視化結果から、適切な意味的制約(λ_sem = 10)は画像構造を保持する一方、不十分な制約(λ_sem = 1)はオブジェクトの混合や意味的劣化を引き起こすことが確認された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。