[論文レビュー] Self-Evaluation Guided Beam Search for Reasoning
著者らは、ステップごとの自己評価に基づく確率的ビームサーチを導入し、多段階推論の自己校正と誘導を行い、計算コストを同等に抑えつつ算術・シンボリック・常識タスクでの精度を強力なベースラインより改善します。
Breaking down a problem into intermediate steps has demonstrated impressive performance in Large Language Model (LLM) reasoning. However, the growth of the reasoning chain introduces uncertainty and error accumulation, making it challenging to elicit accurate final results. To tackle this challenge of uncertainty in multi-step reasoning, we introduce a stepwise self-evaluation mechanism to guide and calibrate the reasoning process of LLMs. We propose a decoding algorithm integrating the self-evaluation guidance via stochastic beam search. The self-evaluation guidance serves as a better-calibrated automatic criterion, facilitating an efficient search in the reasoning space and resulting in superior prediction quality. Stochastic beam search balances exploitation and exploration of the search space with temperature-controlled randomness. Our approach surpasses the corresponding Codex-backboned baselines in few-shot accuracy by $6.34\%$, $9.56\%$, and $5.46\%$ on the GSM8K, AQuA, and StrategyQA benchmarks, respectively. Experiment results with Llama-2 on arithmetic reasoning demonstrate the efficiency of our method in outperforming the baseline methods with comparable computational budgets. Further analysis in multi-step reasoning finds our self-evaluation guidance pinpoints logic failures and leads to higher consistency and robustness. Our code is publicly available at https://guideddecoding.github.io/.
研究の動機と目的
- マルチステップのLLM推論における誤差蓄積を、ステップごとの自己評価メカニズムを導入して軽減する。
- 推論チェーンの探索と活用をバランスさせる制約付き確率的ビームサーチを開発する。
- 生成信頼度と正答信頼度を組み合わせた自己評価スコアによってデコーディングを較正する。
- 算術・シンボリック・常識推論のベンチマークで性能向上を示す。
- 異なるバックボーンやプロンプト手法下でのコストと頑健性を分析する。
提案手法
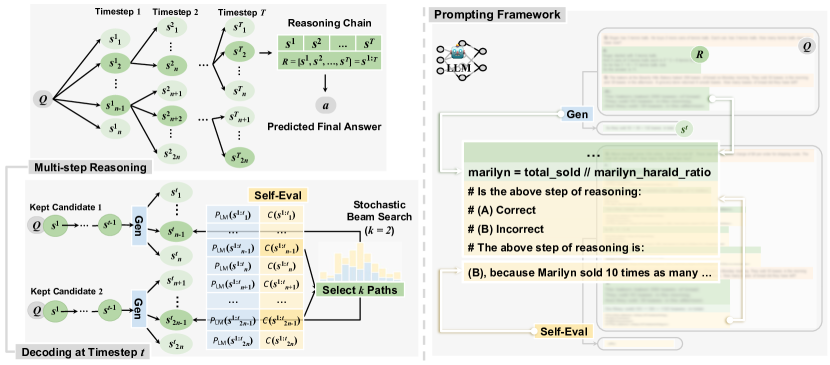
- 各ステップ s^t を意味的に統合されたトークン列として多段デコoding問題として定式化する。
- 各ステップの正解信頼度を表す制約関数 C(s^t) を導入し、目的関数 E(s^{1:T}) の LM 確率とバランスさせて用いる。
- E(s^{1:T}) = prod_t P_{LM_G}^λ(s^t | x, s^{1:t-1}) * C^{1-λ}(s^t) を定義してデコーディングを導く。
- ビームサイズ k の確率的ビームサーチを適用し、ビームごとに n 個の候補をサンプリングして S を形成し、E(s^{1:t})/τ の指数を用いてサンプリング割合で整 diversification を促すことで剪定する。
- ステップ間でのランダム性を徐々に減少させる温度減衰 α を組み込み、長いチェーンを安定化させる。
- 自己評価 LLM(同一バックボーン、プロンプトは別)を用いて、P(A | prompt_C, Q, s^{1:t}) による多択正解スコア C(s^t) を出力する。
- 算術・シンボリック・常識ベンチマークで Codex および Llama-2 の閉鎖ソース・オープンソース LLM を実験し、CoT、PAL/PoT ベースラインおよび self-consistency と比較する。
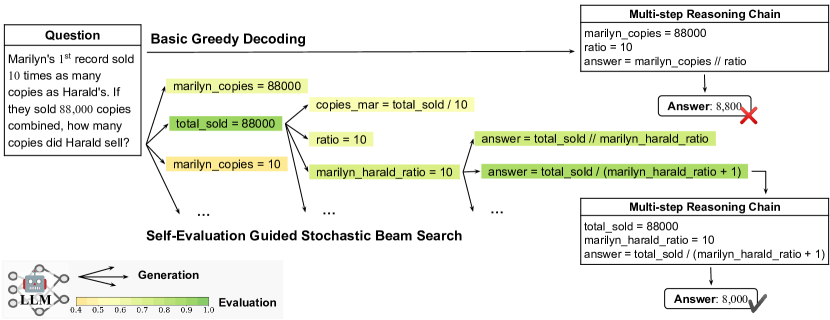
実験結果
リサーチクエスチョン
- RQ1ステップごとの自己評価は、デコーディングを校正・誘導して誤差蓄積を減らすことができるか?
- RQ2制御可能なランダム性を持つ確率的ビームサーチは、固定の計算コストの下で推論品質を向上させるか?
- RQ3提案手法は算術・シンボリック・常識ベンチマークで、強力なベースラインと比較して性能はどうか?
- RQ4自己一貫性や他の prompting 手法と比べた場合のコスト対性能のトレードオフは?
- RQ5生成信頼度と正答信頼度はタスクをまたいで自己評価スコアにどう寄与するか?
主な発見
- 本手法は Codex ベースラインに対して GSM8K、AQuA、StrategyQA の精度を、単独チェーンおよび複数チェーン設定の双方で向上させる。
- Codex を用いた算術推論で Ours-PAL は GSM8K で 85.5%、AQuA で 64.2%、ベースラインの 80.4%、58.6% を上回る。
- Codex を用いた常識推論で Ours-CoT は StrategyQA で 77.2%、CommonsenseQA で 78.6% を達成し、ベースラインの 73.2%、74.4% を上回る。
- コスト分析では本手法は自己一貫性よりトークン使用量が多くなるが、長い推論チェーンでは同等予算下でそれを上回ることがある。
- 生成信頼度と正答信頼度の分析では、正答信頼度が論理的誤りを検出するのにより識別力が高く、λ で両方の信頼度をバランスさせることが結果を改善し、実験では λ=0.5 を使用。
- 長い推論チェーンで効果が大きく、チェーン長が長くなる StrategyQA で特に大きな改善が見られ、ダイバーシティ有効化サンプリングと温度減衰の下でも利得は持続する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。