[論文レビュー] Self-Normalizing Neural Networks
この論文は、SELUs(scaled ELU活性化)と特定の重み初期化に基づくSelf-Normalizing Neural Networks (SNNs) を提案し、 activations を自動的に平均ゼロ・分散単位に近づけることで、バッチ正規化なしで非常に深いネットワークを実現します。理論的保証(固定点の安定性と分散の境界)を提供し、標準的なFNNや正規化ベースの手法と比較して、複数のベンチマークで優れた性能を示します。
Deep Learning has revolutionized vision via convolutional neural networks (CNNs) and natural language processing via recurrent neural networks (RNNs). However, success stories of Deep Learning with standard feed-forward neural networks (FNNs) are rare. FNNs that perform well are typically shallow and, therefore cannot exploit many levels of abstract representations. We introduce self-normalizing neural networks (SNNs) to enable high-level abstract representations. While batch normalization requires explicit normalization, neuron activations of SNNs automatically converge towards zero mean and unit variance. The activation function of SNNs are "scaled exponential linear units" (SELUs), which induce self-normalizing properties. Using the Banach fixed-point theorem, we prove that activations close to zero mean and unit variance that are propagated through many network layers will converge towards zero mean and unit variance -- even under the presence of noise and perturbations. This convergence property of SNNs allows to (1) train deep networks with many layers, (2) employ strong regularization, and (3) to make learning highly robust. Furthermore, for activations not close to unit variance, we prove an upper and lower bound on the variance, thus, vanishing and exploding gradients are impossible. We compared SNNs on (a) 121 tasks from the UCI machine learning repository, on (b) drug discovery benchmarks, and on (c) astronomy tasks with standard FNNs and other machine learning methods such as random forests and support vector machines. SNNs significantly outperformed all competing FNN methods at 121 UCI tasks, outperformed all competing methods at the Tox21 dataset, and set a new record at an astronomy data set. The winning SNN architectures are often very deep. Implementations are available at: github.com/bioinf-jku/SNNs.
研究の動機と目的
- 深く頑健なフィードフォワード網が、過度な正規化手法を用いずに豊かな表現を学習できる必要性を動機付ける。
- 層間で安定した活性化統計を維持するため、SELU 活性化と特定の重み初期化による自己正規化機構を提案する。
- 自己正規化の理論的保証(固定点収束、分散境界)を提供する。
- SNN がさまざまな正規化スキームや競合モデルに対して、 diverse データセットで empirical に優れていることを示す。
提案手法
- SELU 活性化を導入する: selu(x) = lambda x for x>0; lambda*(alpha e^x - alpha) for x<=0, with alpha and lambda chosen to achieve a stable fixed point.
- 層の活性化の平均/分散 mu, nu から次の層の mu~, nu~ への写像 g を、z ~ N(mu*omega, sqrt(nu*tau)) の SELU 変換ガウスのモーメントを用いて定義する; mu~ および nu~ の解析的表現を導出する (Equations 4 and 5)。
- normalized fixed-point behavior のため omega = 0 および tau = 1 で重み初期化を設定する; SELU パラメータ (alpha_01, lambda_01) の下で (mu, nu) が安定な fixed point に収束することを証明する。
- Banach 固定点定理を用いて g が領域 Omega で縮約であることを示し、自己正規化の一意な収束点を保証する。
- 分散境界を確立(定理2および定理3)し、勾配の爆発/消失を防ぎ、nu が多層にわたって制御可能な範囲にとどまることを示す。
- alpha-dropout を導入し、SELUs の平均/分散を保持するドロップアウトの適応で訓練中の自己正規化を維持する。
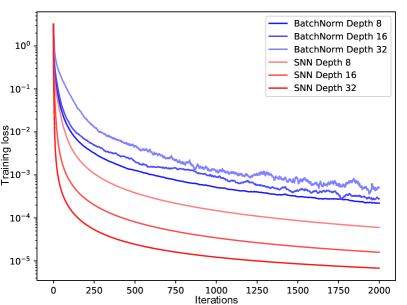
実験結果
リサーチクエスチョン
- RQ1SELU 活性化と特定の初期化により、多層のネットワークで自己正規化を誘導できるか。
- RQ2自己正規化の特性は勾配の消失/爆発を防ぎ、より深い FNN を robust に訓練可能にするか。
- RQ3SNN はバッチ正規化、レイヤ正規化、重み正規化、Highway/ResNet などと比較して diverse benchmarks でどのような性能を示すか。
- RQ4非常に深い SNN が UCI タスク、薬剤発見(Tox21)、天文学データセットでどの程度の経験的利得をもたらすか。
主な発見
- SNN は 121 UCI タスクで対比較において競合する FNN よりも顕著に高い性能を示す。
- Tox21 では、深さが 8 層までの SNN が浅い batchnorm/weightnorm ネットワークを凌駕し、8 層の SNN が最高性能を達成して新しいベンチマークを設定する。
- 天文学(HTRU2 パルサー・データセット)では、SNN が AUC 0.98 の最先端性能を達成し、Naive Bayes、C4.5、SVM のベースラインを上回る。
- SNN は競合よりもはるかに深いアーキテクチャ(平均深さ約 10.8 層)を使用する傾向があり、これが最良の正解率を得る。
- 理論的結果は normalized weights 下で平均/分散の安定な attracting fixed point(0,1)を確立し、分散の境界を提供して勾配の爆発/消失を防ぐ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。