[論文レビュー] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Self-Ragは単一の言語モデルを訓練し、オンデマンドで検索を行い、生成、および反映トークンを介した自身の出力を批評することで、全タスクにおける事実性と引用の正確性を向上させる。
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (Self-RAG) that enhances an LM's quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that Self-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, Self-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
研究の動機と目的
- 多様性を損なうことなく、LLM出力の事実性と検証可能性を向上させる。
- 不必要または関連性の薄い文脈を避けるため、オンデマンド検索を有効にする。
- 取得済みパッセージからの事実性とサポートに基づいて、生成セグメントを批評・格付けする自己反省メカニズムを導入する。
- セグメントごとに検証信号を付与した引用付き出力を提供し、事実確認を促進する。
提案手法
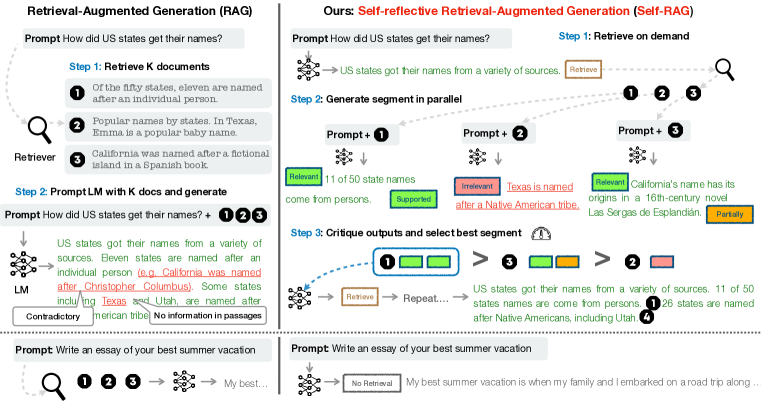
- 検索の必要性を示す反映トークンを用いてテキストを生成し、自身の出力を評価する単一の任意のLMを訓練する。
- モデルがまず取得の有无を決定し、その後複数の取得済みパッセージを並列に処理する、オンデマンド検索を使用する。
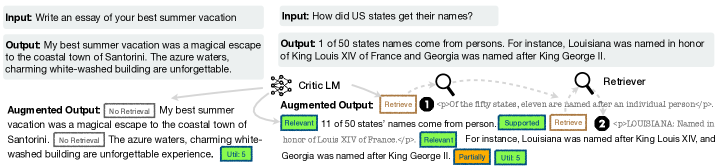
- 取得を制御し、関連性とサポートを評価する4つの反映/批評トークンタイプ(Retrieve、IsRel、IsSup、IsUse)を導入する。
- 批評モデルを活用して、訓練データへ反映トークンをオフラインに挿入し、推論時の外部批評モデルの必要性を削減する。
- 取得済みパッセージと反映トークンを含む拡張データに対して、標準的なLM目的で生成器を訓練する。
- 推論時にはセグメントレベルのビーム探索と反映トークン確率を組み合わせた加重スコアで、カスタマイズ可能なデコード戦略をサポートする。
実験結果
リサーチクエスチョン
- RQ1柔軟性を損なうことなく、生成品質を向上させるためにオンデマンド検索を学習するLMは可能か。
- RQ2反映トークンと批評トークンは長文生成における事実性、検証可能性、引用の正確性を向上させるか。
- RQ3反映トークンに指示されたセグメントレベルの再ランク付けは、取得頻度と出力品質にどのように影響するか。
- RQ4Self-Ragのオンデマンド取得と自己批評が出典の帰属と引用に及ぼす影響は何か。
主な発見
- Self-Ragは、多様なタスクセットで最先端のLLMsおよび検索を組み込んだモデルを著しく上回る。
- Self-RagはChatGPTおよび検索を組み込んだLlama2-chatをOpen-domain QA、推論、事実検証タスクで上回る。
- Self-Ragは長文生成における事実性と引用正確性で、これらのモデルに対して大幅な利得をもたらす。
- 推論時の反映トークンは制御可能な挙動を可能にし、取得頻度やタスク志向の目的の調整を許す。
- オフライン挿入された批評トークンを用いた訓練は、推論時の外部報酬モデルへの依存を減らし、訓練コストを低減する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。