[論文レビュー] Self-Refine: Iterative Refinement with Self-Feedback
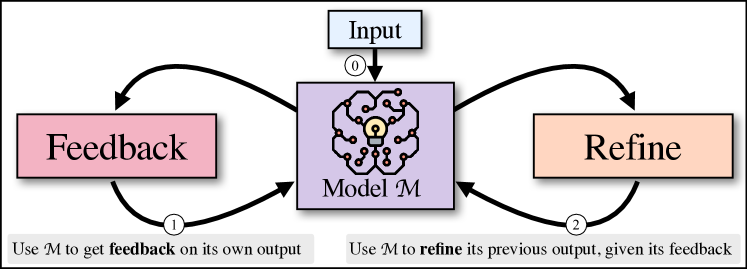
Self-Refine は単一の大規模言語モデルを用いて初期出力を生成し、次にフィードバックを提供して反復的に refinement を行い、追加の訓練なしでタスク全体の改善を達成します。
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce Self-Refine, an approach for improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an initial output using an LLMs; then, the same LLMs provides feedback for its output and uses it to refine itself, iteratively. Self-Refine does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as the generator, refiner, and feedback provider. We evaluate Self-Refine across 7 diverse tasks, ranging from dialog response generation to mathematical reasoning, using state-of-the-art (GPT-3.5, ChatGPT, and GPT-4) LLMs. Across all evaluated tasks, outputs generated with Self-Refine are preferred by humans and automatic metrics over those generated with the same LLM using conventional one-step generation, improving by ~20% absolute on average in task performance. Our work demonstrates that even state-of-the-art LLMs like GPT-4 can be further improved at test time using our simple, standalone approach.
研究の動機と目的
- 人間の文章作成と問題解決に触発された反復的自己フィードバックを介してLLM出力の改善を動機づける。
- 同じLLMを生成・フィードバック・改良に用いる訓練不要の方法を提案する。
- 多様なタスクでの有効性を実証し、フィードバック品質と反復深さの影響を分析する。
提案手法
- ベースLLMで初期出力を生成する。
- 同じLLMに対して、その出力について実用的なフィードバックを生成するよう促す。
- 改良されたプロンプトを用いて同じLLMにフィードバックを反映させて出力を改良する。
- タスク固有の停止条件までフィードバックと改良を繰り返す(最大4回の反復)。
- 外部の訓練なしで、Few-shotプロンプトを用いて生成・フィードバック・改良を導く。
実験結果
リサーチクエスチョン
- RQ1追加の訓練なしで、単一のLLMが自己フィードバックと改良を通じて自身の出力を改善できるか?
- RQ2自己生成フィードバックの品質が改良結果にどのように影響するか?
- RQ3複数回のフィードバック-改良反復がさまざまなタスクに与える影響は?
- RQ4自己改良は多様なドメインにおいて単回生成を上回るか?
主な発見
| タスク | GPT-3.5 Base | GPT-3.5 + Ours | ChatGPT Base | ChatGPT + Ours | GPT-4 Base | GPT-4 + Ours |
|---|---|---|---|---|---|---|
| Sentiment Reversal | 8.8 | 30.4 (↑ 21.6) | 11.4 | 43.2 (↑ 31.8) | 3.8 | 36.2 (↑ 32.4) |
| Dialogue Response | 36.4 | 63.6 (↑ 27.2) | 40.1 | 59.9 (↑ 19.8) | 25.4 | 74.6 (↑ 49.2) |
| Code Optimization | 14.8 | 23.0 (↑ 8.2) | 23.9 | 27.5 (↑ 3.6) | 27.3 | 36.0 (↑ 8.7) |
| Code Readability | 37.4 | 51.3 (↑ 13.9) | 27.7 | 63.1 (↑ 35.4) | 27.4 | 56.2 (↑ 28.8) |
| Math Reasoning | 64.1 | 64.1 (0) | 74.8 | 75.0 (↑ 0.2) | 92.9 | 93.1 (↑ 0.2) |
| Acronym Generation | 41.6 | 56.4 (↑ 14.8) | 27.2 | 37.2 (↑ 10.0) | 30.4 | 56.0 (↑ 25.6) |
| Constrained Generation | 28.0 | 37.0 (↑ 9.0) | 44.0 | 67.0 (↑ 23.0) | 15.0 | 45.0 (↑ 30.0) |
- 7つのタスクにおいて、自己改良は一度生成と比較して人間および自動の評価で好ましさが高い。
- GPT-4 with self-refine は顕著な絶対的向上を示す(例:Code Optimization が27.3% から36.0%へ; +8.7)。
- 好みベースのタスクでは、向上が特に大きい(例:Dialogue Response: GPT-4 は25.4から74.6へ)。
- 反復的なフィードバック後に探索する出力が多くなることで、Constrained Generation は大きく恩恵を受ける。
- Codeベースのタスクも向上し、Codex を使用すると絶対的な gains が最大で13%。
- 実用的で具体的なフィードバックは性能にとって不可欠であり、一般的またはフィードバックなしは結果を低下させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。