[論文レビュー] Self-Supervised Learning for Recommender Systems: A Survey
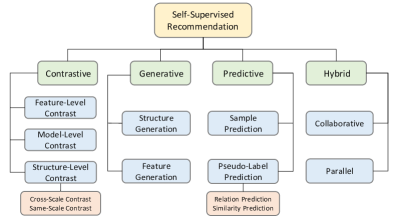
この調査は自己教師付き推奨(SSR)を定義し、4カテゴリの分類法(対照型、生成型、予測型、ハイブリッド型)を提案し、SELFRecを導入し、推奨システムのSSR手法と今後の方向性を分析します。
In recent years, neural architecture-based recommender systems have achieved tremendous success, but they still fall short of expectation when dealing with highly sparse data. Self-supervised learning (SSL), as an emerging technique for learning from unlabeled data, has attracted considerable attention as a potential solution to this issue. This survey paper presents a systematic and timely review of research efforts on self-supervised recommendation (SSR). Specifically, we propose an exclusive definition of SSR, on top of which we develop a comprehensive taxonomy to divide existing SSR methods into four categories: contrastive, generative, predictive, and hybrid. For each category, we elucidate its concept and formulation, the involved methods, as well as its pros and cons. Furthermore, to facilitate empirical comparison, we release an open-source library SELFRec (https://github.com/Coder-Yu/SELFRec), which incorporates a wide range of SSR models and benchmark datasets. Through rigorous experiments using this library, we derive and report some significant findings regarding the selection of self-supervised signals for enhancing recommendation. Finally, we shed light on the limitations in the current research and outline the future research directions.
研究の動機と目的
- SSRを定義し、事前学習や標準的なコントラスト学習などの関連パラダイムと区別する。
- SSR手法を4つのカテゴリー(対照型、生成型、予測型、ハイブリッド型)に分類する分類法を開発する。
- SSRで用いられるデータ拡張手法と訓練スキームをまとめる。
- SSR設計を指針とするオープンソースフレームワーク(SELFRec)と実証的な知見を提供する。
- 推奨システムのSSRにおける制限と今後の方向性について議論する。
提案手法
- 拡張データからの半自動監視と推奨を強化する自己教師ありタスクに基づく、SSRの正式な定義を提案する。
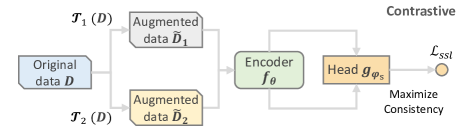
- グラフ、系列、カテゴリ特徴を扱える統一されたエンコーダー+プロジェクションヘッドアーキテクチャを導入する。
- SSR手法を4カテゴリー(対照型、生成型、予測型、ハイブリッド)に分類し、それぞれの目的と損失(L_rec、L_ssl)を示す。
- 自己教師付きタスクと推奨を組み合わせるための3つの訓練スキーム(Joint Learning、Pre-training and Fine-tuning、Integrated Learning)を概説する。
- 系列、グラフ、特徴量に対して一般的に用いられるデータ拡張手法を提示・要約する。
- ベンチマークと20超のSSR手法を含むオープンソースライブラリSELFRecを提供する。
実験結果
リサーチクエスチョン
- RQ1SSRと関連パラダイムからの区別を最もよく捉える正式な定義は何か?
- RQ2推奨システム向けにSSR手法を体系的に分類するにはどうするべきか?
- RQ3SSRにおける効果的なデータ拡張戦略と訓練スキームは何か?
- RQ4SELFRecを用いた経験的比較から得られる自己教師信号による推奨の向上に関する洞察は何か?
- RQ5SSR研究の現状の制約と有望な方向性は何か?
主な発見
- SSRは4つのカテゴリーにわたる多様な自己監視信号から利益を得ており、各カテゴリーには固有のトレードオフがある。
- データ拡張はSSRの転用可能な表現を学ぶ上で重要な役割を果たす。
- Joint Learningが最も一般的な訓練スキームであり、Pre-training and Fine-tuningはBERT風の生成型SSRモデルで普及している。
- オープンソースのSELFRecライブラリはSSR手法の再現性ある評価とベンチマークを可能にする。
- SELFRecの実証的結果は自己教師信号の効果的な選択と推奨目的とタスクの整合性の重要性を強調している。
- この調査は制限を特定し、推奨におけるSSRを進展させる今後の方向性を概説している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。