[論文レビュー] Self-Training and Adversarial Background Regularization for Unsupervised Domain Adaptive One-Stage Object Detection
本稿では、弱い自己学習(WST)と敵対的バックグラウンドスコア正則化(BSR)を提案し、教師なしドメイン適応型1段階オブジェクト検出の性能を向上させる。WSTは、ハードネガティブな偽ラベルの勾配をマスクし、SRRSを用いて信頼性の高い偽ラベルを生成することで自己学習を安定化させる。一方、BSRは、ターゲットドメインにおけるフォアグラウンド・バックグラウンドの区別を強化する。本手法は、ターゲットドメインのアノテーションを一切用いず、標準ベンチマークで最先端のmAP向上を達成した。
Deep learning-based object detectors have shown remarkable improvements. However, supervised learning-based methods perform poorly when the train data and the test data have different distributions. To address the issue, domain adaptation transfers knowledge from the label-sufficient domain (source domain) to the label-scarce domain (target domain). Self-training is one of the powerful ways to achieve domain adaptation since it helps class-wise domain adaptation. Unfortunately, a naive approach that utilizes pseudo-labels as ground-truth degenerates the performance due to incorrect pseudo-labels. In this paper, we introduce a weak self-training (WST) method and adversarial background score regularization (BSR) for domain adaptive one-stage object detection. WST diminishes the adverse effects of inaccurate pseudo-labels to stabilize the learning procedure. BSR helps the network extract discriminative features for target backgrounds to reduce the domain shift. Two components are complementary to each other as BSR enhances discrimination between foregrounds and backgrounds, whereas WST strengthen class-wise discrimination. Experimental results show that our approach effectively improves the performance of the one-stage object detection in unsupervised domain adaptation setting.
研究の動機と目的
- ソースドメインとターゲットドメインのデータ分布が異なる場合に生じるドメインシフトの課題に対処すること。
- 不正確な偽ラベルによる性能低下を軽減することで、教師なしドメイン適応における自己学習の安定化を図ること。
- 非転送可能なターゲットドメインのバックグラウンド特徴を強化することで、ドメインシフトを低減すること。
- 従来の弱教師ありアプローチとは異なり、ターゲットドメインに画像レベルのラベルが不要な有効な自己学習を可能にすること。
- 限られたもしくはラベルのないターゲットデータにおける実世界の展開状況において、1段階検出器の一般化性能を向上させること。
提案手法
- 信頼性の高い偽ラベルをフィルタリングし、誤検出と見逃しを低減するためにSRRS(サポートリージョンベースの信頼性スコア)を用いる弱い自己学習(WST)を導入する。
- 自己学習中にハードネガティブ例に対して勾配マスクを適用し、誤ったバックグラウンド予測によるモデルの崩壊を防ぐ。
- 学習の安定化のため、元のネガティブセットから簡単なネガティブ例のみを抽出して、洗練されたネガティブセット $\widetilde{\text{Neg}}$ を構築する。
- ハイパーパrameter $\gamma$ と $t$ を用いたフォーカル損失に類似した目的関数を用いて、敵対的バックグラウンドスコア正則化(BSR)を提案する。
- ソースデータに対する教師あり損失と、WSTおよびBSRのコンponentsを含むターゲットデータに対する自己学習損失の組み合わせで検出器を訓練する。
- 特徴のアライメントを図るドメイン識別器を用いるが、BSRの焦点はグローバル特徴アライメントではなく、フォアグラウンド・バックグラウンドの区別を向上させることに置く。
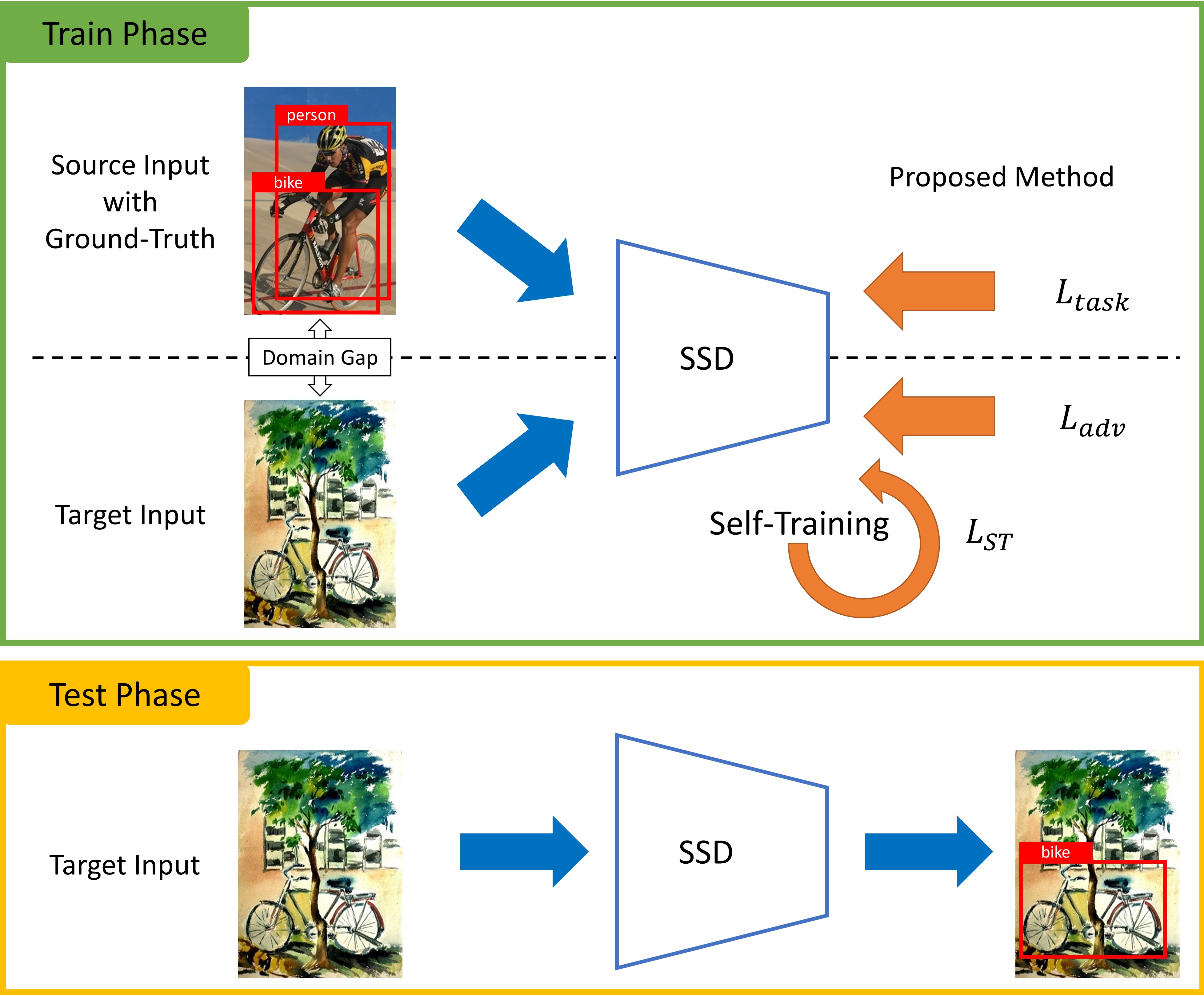
実験結果
リサーチクエスチョン
- RQ1画像レベルのラベルに依存せずに、教師なしドメイン適応型1段階オブジェクト検出における自己学習を安定化させることは可能か?
- RQ2偽ラベルにおける誤検出と見逃しを効果的に低減することで、性能の低下を防ぐにはどうすればよいか?
- RQ3バックグラウンド特徴の区別を強化することで、1段階検出器におけるドメインシフトはどの程度低減されるか?
- RQ4BSRにおけるハイパーパrameter $\gamma$ と $t$ は、モデルの安定性と精度にどのように影響するか?
- RQ5WSTとBSRの組み合わせは、それぞれのコンponent単体よりも、ドメインシフトの低減と検出mAPの向上においてより効果的か?
主な発見
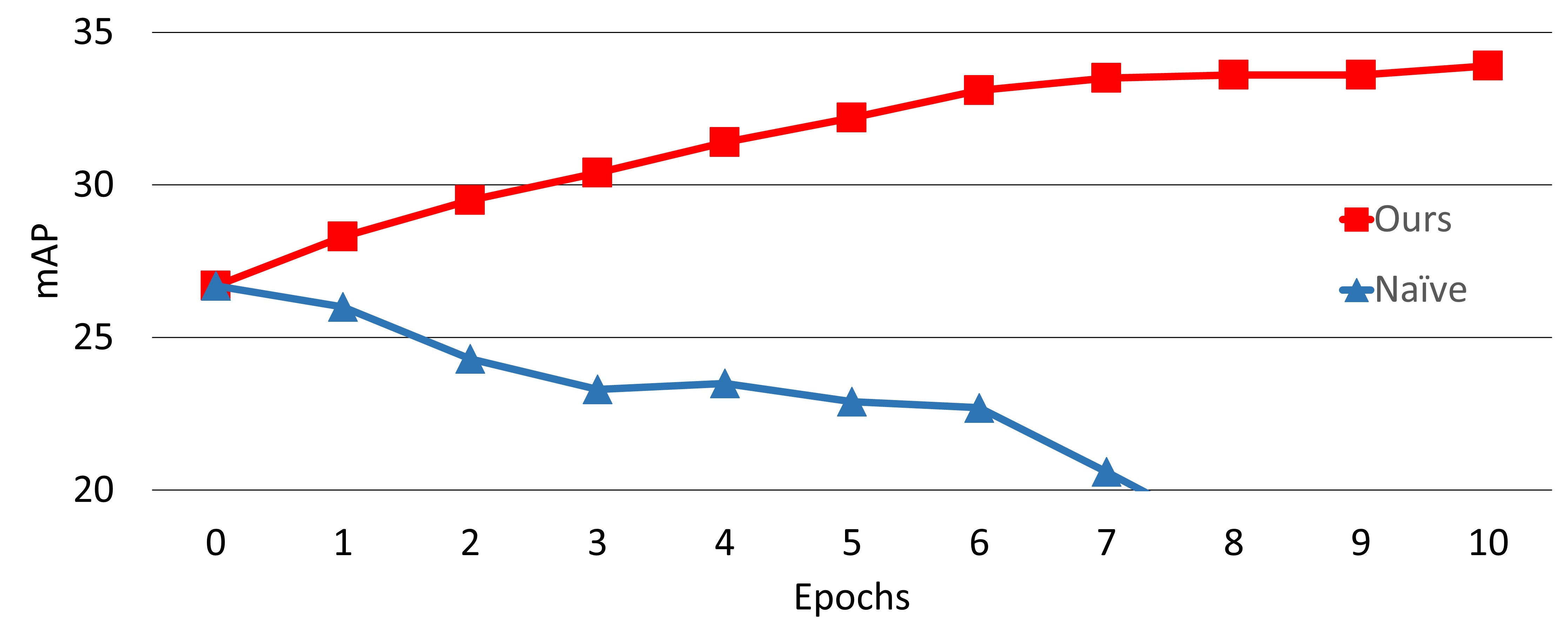
- 提案されたWST手法は、Watercolor2kデータセットで34.0%のmAPを達成し、ナードフォールバックの自己学習(19.8%)や他のベースラインを大きく上回った。
- SRRSと弱いネガティブマイニングを組み合わせることで、Clipart1kでベースネットワーク比で14.5%のmAP向上を達成し、信頼性のあるネガティブ例の選択の有効性を示した。
- BSRにおいて $\gamma=0.5$ と $t=0.5$ の組み合わせが最良の性能を示し、中程度の正則化強度が最適であり、過度な正則化は学習に悪影響を及えることがわかった。
- アブレーションスタディにより、SRRSと弱いネガティブマイニングの両方が不可欠であることが確認された。いずれかを除去すると、性能が急速に低下した。
- 可視化結果から、提案手法は特にごみだらけの背景においても、より高い信頼度でオブジェクトを検出でき、誤検出が少ないことが示された。
- 標準ベンチマーク(例:COCO-to-Clipart、COCO-to-Watercolor)において、教師なしドメイン適応設定下で最先端の性能を達成した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。