[論文レビュー] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SelfCheckGPTは外部データベースを用いず、生成型LLMを対象とするゼロリソースのブラックボックス幻覚検出アプローチで、情報的一貫性を評価し外部データベースなしで非事実的内容を検出する。
Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods.
研究の動機と目的
- 外部知識ベースを用いずにブラックボックスLLMにおける事実的な幻覚の課題を動機づけ、対処する。
- 複数のLLMサンプル間の一貫性を測定するサンプリングベースのフレームワーク(SelfCheckGPT)を提案する。
- WikiBio由来のGPT-3データセットに対して、文レベルおよび段落レベルの事実性ラベルを用いたグレーボックスおよびブラックボックスのベースラインと比較して評価する。
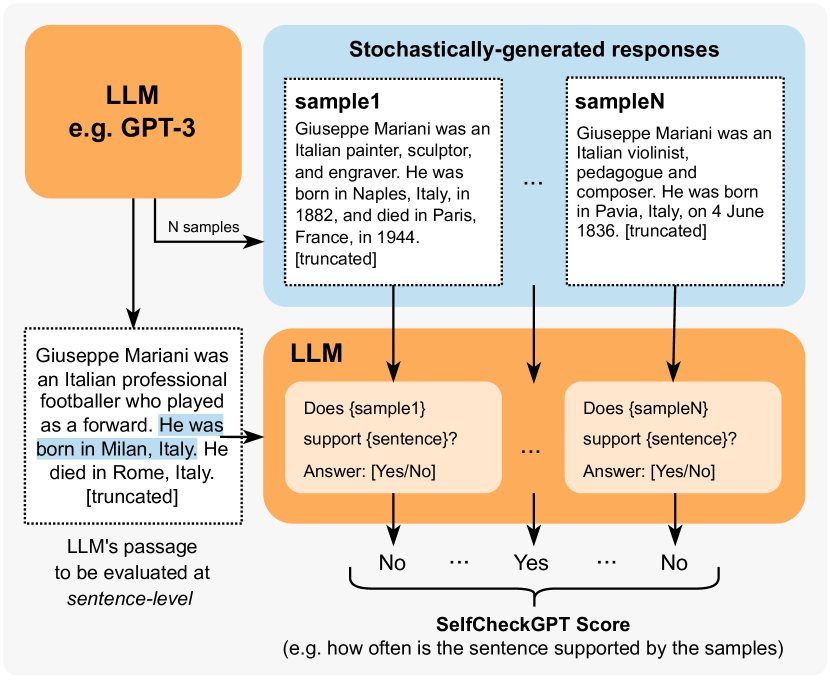
提案手法
- 特定のプロンプトに対して、同じLLMからN個の確率的サンプルを生成する。
- BERTScore、QAベースの一貫性、 unigram max n-gram、NLI、およびプロンプトベースの prompting を用いて文レベルの事実性スコアを計算する。
- n-gramの場合、サンプルと主応答に基づいて単純なn-gramモデルを訓練し、トークンの確率を推定する。
- 文評価のためにNLI(MNLIでファインドチューニングされたDeBERTa-v3-large)を用いて矛盾確率を算出する。
- プロンプトベースの評価者(SelfCheckGPT-Prompt)を用いて、サンプル化された文脈により文がサポートされているかをLLMに問い合わせる。
- 文レベルのスコアを報告し、平均化によって段落レベルのスコアに集約する。
実験結果
リサーチクエスチョン
- RQ1外部データベースを使わず、ゼロリソースかつブラックボックスのサンプリングで事実的な文と非事実的な文を検出できるか。
- RQ2SelfCheckGPTのどのバリアントが文レベルおよび段落レベルの事実性に関する人間の判断と最も高い相関を示すか。
- RQ3検出性能と人間の評価との相関において、SelfCheckGPTはグレーボックスおよび他のブラックボックス手法とどのように比較されるか?
主な発見
| 方法 | 非事実 | 非事実* | 事実的 | Pearson | Spearman |
|---|---|---|---|---|---|
| Random | 72.96 | 29.72 | 27.04 | - | - |
| GPT-3 probabilities (LLM, grey-box) Avg(-log p) | 83.21 | 38.89 | 53.97 | 57.04 | 53.93 |
| GPT-3 probabilities (LLM, grey-box) Avg(H) | 80.73 | 37.09 | 52.07 | 55.52 | 50.87 |
| GPT-3 probabilities (LLM, grey-box) Max(-log p) | 87.51 | 35.88 | 50.46 | 57.83 | 55.69 |
| GPT-3 probabilities (LLM, grey-box) Max(H) | 85.75 | 32.43 | 50.27 | 52.48 | 49.55 |
| LLaMA-30B (Proxy LLM, black-box) Avg(-log p) | 75.43 | 30.32 | 41.29 | 21.72 | 20.20 |
| LLaMA-30B (Proxy LLM, black-box) Avg(H) | 80.80 | 39.01 | 42.97 | 33.80 | 39.49 |
| LLaMA-30B (Proxy LLM, black-box) Max(-log p) | 74.01 | 27.14 | 31.08 | -22.83 | -22.71 |
| LLaMA-30B (Proxy LLM, black-box) Max(H) | 80.92 | 37.32 | 37.90 | 35.57 | 38.94 |
| SelfCheckGPT w/ BERTScore | 81.96 | 45.96 | 44.23 | 58.18 | 55.90 |
| SelfCheckGPT w/ QA | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
| SelfCheckGPT w/ Unigram (max) | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| SelfCheckGPT w/ NLI | 92.50 | 45.17 | 66.08 | 74.14 | 73.78 |
| SelfCheckGPT w/ Prompt | 93.42 | 53.19 | 67.09 | 78.32 | 78.30 |
- SelfCheckGPTのバリアントは、非事実的および事実的な文に対して文レベルのAUC-PRでいくつかのベースラインより高い値を達成する。
- NLIベースのSelfCheckGPTは高い性能を達成し、文レベル検出においてPromptベースの評価に近づく。
- PromptベースのSelfCheckGPTは人間の判断との段落レベルの相関で最良を示す(Pearson 78.32、Spearman 78.30)。
- NLIベースのSelfCheckGPTは性能と計算量の現実的なトレードオフを提供する。
- Unigram最大n-gram SelfCheckGPTは、比較的低い計算コストで競争力のある文レベルの結果を提供する。
- 代理LLM(例:LLaMA)と比較して、自己サンプリングベースの手法は人間の判断との相関が優れている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。