[論文レビュー] SELFormer: Molecular Representation Learning via SELFIES Language Models
SELFormer は SELFIES 入力を用いるトランスフォーマーベースの化学言語モデルで、2百万の ChEMBL 分子で事前学習し、分子特性予測のためにファインチューニングされ、主要なタスクで SMILES ベースおよびグラフベースの手法を上回る。
Automated computational analysis of the vast chemical space is critical for numerous fields of research such as drug discovery and material science. Representation learning techniques have recently been employed with the primary objective of generating compact and informative numerical expressions of complex data. One approach to efficiently learn molecular representations is processing string-based notations of chemicals via natural language processing (NLP) algorithms. Majority of the methods proposed so far utilize SMILES notations for this purpose; however, SMILES is associated with numerous problems related to validity and robustness, which may prevent the model from effectively uncovering the knowledge hidden in the data. In this study, we propose SELFormer, a transformer architecture-based chemical language model that utilizes a 100% valid, compact and expressive notation, SELFIES, as input, in order to learn flexible and high-quality molecular representations. SELFormer is pre-trained on two million drug-like compounds and fine-tuned for diverse molecular property prediction tasks. Our performance evaluation has revealed that, SELFormer outperforms all competing methods, including graph learning-based approaches and SMILES-based chemical language models, on predicting aqueous solubility of molecules and adverse drug reactions. We also visualized molecular representations learned by SELFormer via dimensionality reduction, which indicated that even the pre-trained model can discriminate molecules with differing structural properties. We shared SELFormer as a programmatic tool, together with its datasets and pre-trained models. Overall, our research demonstrates the benefit of using the SELFIES notations in the context of chemical language modeling and opens up new possibilities for the design and discovery of novel drug candidates with desired features.
研究の動機と目的
- 学習のために100%有効かつ頑健な分子表現の改善を動機づける
- 堅牢な文字列ベースの分子表記である SELFIES をトランスフォーマー言語モデルと組み合わせて活用する
- 大規模な薬物様分子コーパスで事前学習し、多様な性質予測タスクにファインチューニングする
- 複数のベンチマークで SMILES ベースおよびグラフベースのモデルと性能を比較する
- 研究コミュニティに対してコード、データセット、および事前学習済みモデルを公開アクセスで提供する
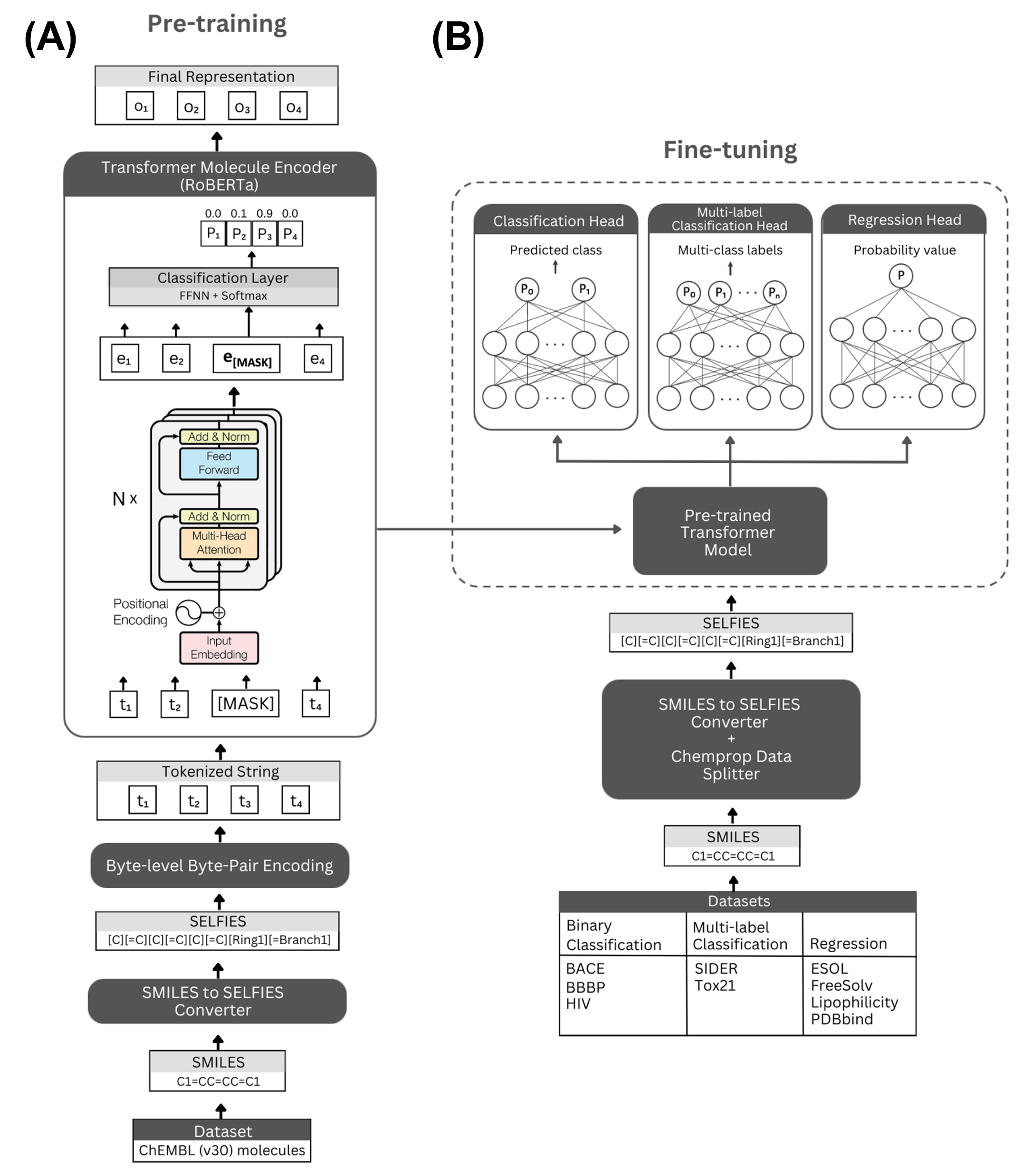
提案手法
- SMILES を SELFIES に変換し、RoBERTa に類似したバイトレベル BPE でトークン化する
- 2M ChEMBL 分子を対象に、マスク付き言語モデルで RoBERTa 類似のトランスフォーマーエンコーダを事前学習する
- SELFormer および SELFormer-Lite を選択するために、アテンションヘッド数、層数、学習率、バッチサイズ、エポック数などのハイパーパラメータ探索を実施する
- 前処理済みモデルを MoleculeNet の分類および回帰タスクに、2 層の線形ヘッドを用いてファインチューニングする
- 分類は ROC-AUC および PRC、回帰は RMSE で評価し、スキャフォールド分割とランダム分割を用いる
- 事前学習済みモデルと表現を公開する
実験結果
リサーチクエスチョン
- RQ1SELFIES ベースのトランスフォーマーは、SMILES ベースのモデルよりも堅牢な分子表現を学習できるのだろうか?
- RQ2大規模なSELFIESコーパスでの事前学習は、下流の分子特性予測性能にどのような影響を与えるか?
- RQ3標準的な MoleculeNet タスクにおいて、ファインチューニングと事前学習済み表現を使用することの影響は何か?
- RQ4分類および回帰のベンチマークにおいて、SELFIES ベースのモデルはグラフベースおよび SMILES ベースの言語モデルとどう比較されるか?
主な発見
- SELFormer は水性溶解度および薬物動態関連副作用予測(SIDER、ESOL など)で競合他手法を上回る。
- 他の下流タスクでも SELFIES ベースのモデルは他手法と同程度の結果を達成する。
- 重いファインチューニング前の事前学習表現は、視覚化分析で見られるように、異なる構造特性を持つ分子をすでに識別する。
- アブレーション研究により、SELFormer はほとんどのタスクで軽量版の SELFormer-Lite を一貫して上回り、ファインチューニングが性能を向上させることが示される。
- 最適化されたハイパーパラメータでのファインチューニングは、いくつかのベンチマークで顕著な向上をもたらし、SELFIES は立体化学に敏感なタスクの性能向上に寄与する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。