[論文レビュー] SemEval-2023 Task 10: Explainable Detection of Online Sexism
論文は、説明可能なオンライン性差別検出のためのEDOSという三タスク階層型分類法、20kラベルのデータセット、多様なプラットフォーム、そしてパフォーマンスのギャップと説明性の課題を強調するベースライン/参加者結果を紹介します。
Online sexism is a widespread and harmful phenomenon. Automated tools can assist the detection of sexism at scale. Binary detection, however, disregards the diversity of sexist content, and fails to provide clear explanations for why something is sexist. To address this issue, we introduce SemEval Task 10 on the Explainable Detection of Online Sexism (EDOS). We make three main contributions: i) a novel hierarchical taxonomy of sexist content, which includes granular vectors of sexism to aid explainability; ii) a new dataset of 20,000 social media comments with fine-grained labels, along with larger unlabelled datasets for model adaptation; and iii) baseline models as well as an analysis of the methods, results and errors for participant submissions to our task.
研究の動機と目的
- 説明可能な性差別検出の階層型分類法を提案する(バイナリ、カテゴリ、および細粒度ベクトル)。
- RedditとGabからの専門家アノテータによる、多様で注釈付きのデータセットを構築する。
- 強力なベースラインを提供し、参加者の方法を分析して課題と誤分類のタイプを特定する。
- 三つの階層タスクでシステムを評価し、精度と説明性の両方を評価する。
提案手法
- 三段階の分類法を設計する:Task A(バイナリ性差別)、Task B(4カテゴリ)、Task C(11の細粒度ベクトル)。
- RedditとGabから20kのラベル付きコメントを6つの多様なサンプリング手法で収集・サンプリングし、ドメイン内の未ラベルデータ200万件を補足する。
- 19名の専門家女性アノテータで注釈を行い、相違を解決するための裁定を行い、低一致ケースには専門家アノテータを用いる。
- データを訓練/開発/テスト(70/10/20)に分割し、継続的な事前学習ベースラインのため未ラベルデータを公開する。
- Task A–CのマクロF1を報告し、CodaLabでの参加者提出を可能にする7つのベースライン(TF-IDF+XGBoost、DistilBERT、DeBERTa系などを含む)を提供する。
- 誤り分析(混同行列、手動検査)を実施し、誤分類とアノテーションの課題を理解する。
実験結果
リサーチクエスチョン
- RQ1階層型分類法は、2値ラベルを超えた説明性の向上につながるか?
- RQ2多様なソーシャルプラットフォームにおけるTask A(バイナリ)、Task B(カテゴリ)、Task C(ベクトル)での性能と誤り特性はどうなるか?
- RQ3ドメイン内の未ラベルデータでの継続的な事前学習は、各タスクの性能にどのように影響するか?
- RQ4ニュアンスのある性差別ベクトルのアノテーション時の一般的な誤りパターンと課題とは何か?
主な発見
| Model | Task A | Task B | Task C |
|---|---|---|---|
| B0 (MostFrequent) | 0.4310 | 0.1594 | 0.0317 |
| B1 (Uniform) | 0.4509 | 0.2413 | 0.0629 |
| B2 (XGBoost) | 0.4933 | 0.2297 | 0.0881 |
| B3 (DistilBERT) | 0.7621 | 0.5531 | 0.2935 |
| B4 (DistilBERT + unlabelled data) | 0.7804 | 0.5367 | 0.3140 |
| B5 (DeBERTa-v3-base) | 0.8235 | 0.4790 | 0.1517 |
| B6 (DeBERTa-v3-base + unlabelled data) | 0.8235 | 0.5926 | 0.3171 |
| PingAnLifeInsurance | 0.8746 | — | — |
| stce | 0.8740 | 0.7203 | 0.5487 |
| FiRC-NLP | 0.8740 | — | — |
| JUAGE | — | 0.7326 | — |
| PASSTeam | 0.7212 | 0.5412 | 0.5412 |
| PALI | 0.5606 | — | — |
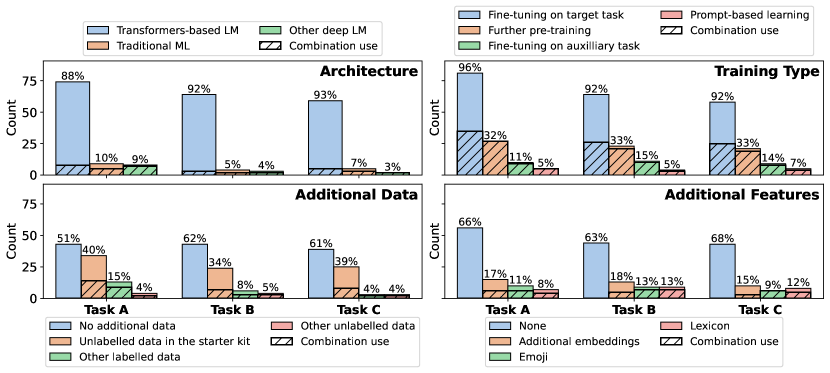
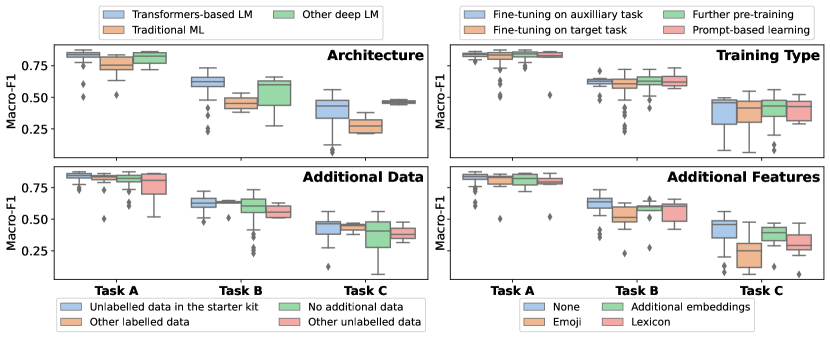
- Task Aのベースライン(DeBERTa-v3)は最大のマクロ-F1が約0.8235で、Task B/Cははるかに難しく(ベースラインで0.5926と0.3171)。
- エンサンブル法と未ラベルのドメイン内データでの継続的事前学習が、参加者システムの中で最高の成果を生んだ。
- トランスフォーマー系アーキテクチャが提出の中心で、RoBERTa/DeBERTa系およびプロンプトベースモデルが最も良好な性能を示す一方で、追加の特徴は性能をほとんど向上させなかった。
- 誤り分析では、Task Aで偽陰性が偽陽性より多く、敵意と非難が多くの誤分類を生み出していた。
- 細粒度タスク(BとC)は大きな余地を示す;最大Task CのマクロF1スコアはベースラインで約0.32、上位システムでは一部タスクで約0.55–0.60程度に達する。
- アノテーションの質と文脈的ニュアンスは依然として重要な課題であり、いくつかの人間アノテーションの不一致とグレーエリアのケースが存在する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。