[論文レビュー] SEPT: Towards Efficient Scene Representation Learning for Motion Prediction
SEPTはシーン入力に対する3つの自己教師付きマスキングタスクを用いてシーンエンコーダを事前学習し、その後モーション予測のためにファインチューニングを行い、コンパクトなアーキテクチャでArgoverse 1および2において最先端の結果を達成します。
Motion prediction is crucial for autonomous vehicles to operate safely in complex traffic environments. Extracting effective spatiotemporal relationships among traffic elements is key to accurate forecasting. Inspired by the successful practice of pretrained large language models, this paper presents SEPT, a modeling framework that leverages self-supervised learning to develop powerful spatiotemporal understanding for complex traffic scenes. Specifically, our approach involves three masking-reconstruction modeling tasks on scene inputs including agents' trajectories and road network, pretraining the scene encoder to capture kinematics within trajectory, spatial structure of road network, and interactions among roads and agents. The pretrained encoder is then finetuned on the downstream forecasting task. Extensive experiments demonstrate that SEPT, without elaborate architectural design or manual feature engineering, achieves state-of-the-art performance on the Argoverse 1 and Argoverse 2 motion forecasting benchmarks, outperforming previous methods on all main metrics by a large margin.
研究の動機と目的
- 交通環境からシーン理解を学習し、効率的で正確なモーション予測を動機づける。
- 道路シーンの時間的・空間的・相互作用の手がかりを捉える自己教師付き事前学習スキームを開発。
- 三つのマスキング再構成タスクでシーンエンコーダを事前学習し、下流予測のためにファインチューニング。
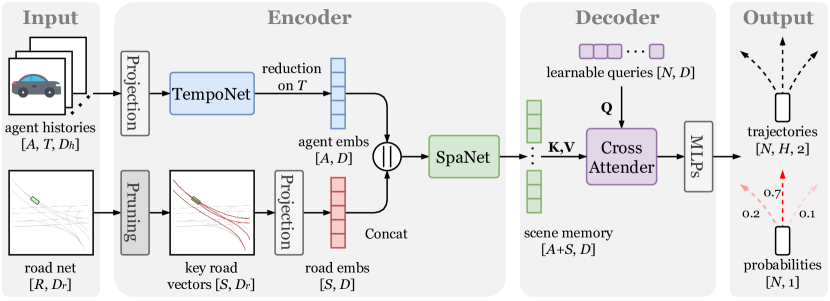
提案手法
- エージェントと道路ネットワークを軌跡と道路ベクトル入力として表現。
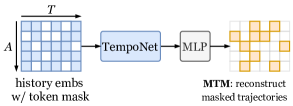
- 三つのタスクで事前学習: Marked Trajectory Modeling (MTM), Masked Road Modeling (MRM), Tail Prediction (TP).
- MTMは軌道ウェイポイントをマスクし再構成して時間的依存を学習。
- MRMは道路ベクトル属性をマスクし道路トポロジーと接続性を学習。
- TPは頭部軌道と道路コンテキストから尾部軌道を予測し、時間的および空間的表現を整合。
- TempoNet(時間的エンコーダ)とSpaNet(空間的エンコーダ)をCross Attenderと組み合わせ、統一されたトランスフォーマーベースのパイプラインで予測。
- 事前学習済みエンコーダを下流の軌道予測デコーダでファインチューニングし、回帰と分類の結合損失を最適化。
実験結果
リサーチクエスチョン
- RQ1時間的・空間的・相互作用の手がかりに基づく自己教師付き事前学習はモーション予測性能を向上させるか。
- RQ2MTM、MRM、TPは下流予測性能に加法的に寄与するか。
- RQ3コンパクトな単一アーキテクチャのエンコーダで大規模なモーション予測ベンチマークでSOTAを達成できるか。
主な発見
- 事前学習は主要なモーション予測指標でスクラッチからの学習より一貫した改善をもたらす。
- 3つの事前学習タスクはいずれも性能に加法的に寄与し、Tail Prediction (TP) は時間的表現と空間的表現の整合を大きく支援する。
- SEPTはArgoverse 1およびArgoverse 2でSOTAを達成し、主要指標で1位、最強のベースラインと比較して約40%のパラメータ、推論も高速。
- Argoverse 1ではほとんどの指標で1位、Argoverse 2では報告された方法の中で全指標で1位。
- SEPTは約9.6Mパラメータのコンパクトなエンコーダ設計で推論が速く、精度も競争力があるか上回る。
- アブレーションによりTPがTempoNetとSpaNetを結合するうえで重要であり、MTMとMRMが加法的改善を提供。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。