[論文レビュー] Seven Failure Points When Engineering a Retrieval Augmented Generation System
本稿は、3つのケーススタディにおいてRAGシステムで観察された7つの障害点を提示し、頑健性と評価のための実践的な教訓と今後の研究指針を導出する。さらに、BioASQや他のドメイン展開からの実証的知見を提供し、実務者を導く。
Software engineers are increasingly adding semantic search capabilities to applications using a strategy known as Retrieval Augmented Generation (RAG). A RAG system involves finding documents that semantically match a query and then passing the documents to a large language model (LLM) such as ChatGPT to extract the right answer using an LLM. RAG systems aim to: a) reduce the problem of hallucinated responses from LLMs, b) link sources/references to generated responses, and c) remove the need for annotating documents with meta-data. However, RAG systems suffer from limitations inherent to information retrieval systems and from reliance on LLMs. In this paper, we present an experience report on the failure points of RAG systems from three case studies from separate domains: research, education, and biomedical. We share the lessons learned and present 7 failure points to consider when designing a RAG system. The two key takeaways arising from our work are: 1) validation of a RAG system is only feasible during operation, and 2) the robustness of a RAG system evolves rather than designed in at the start. We conclude with a list of potential research directions on RAG systems for the software engineering community.
研究の動機と目的
- 研究、教育、医関係を含む複数の領域で実用的な障害点を特定することにより、頑健なRAGエンジニアリングを促進する。
- RAG設計の選択を導くための経験的根拠に基づく障害点のカタログを提供する。
- 3つのRAG展開からの教訓を共有し、RAGの頑健性とテストに関するソフトウェア工学研究を導く。
- RAGシステムにおけるチャンク化/埋め込み、チューニング戦略、テスティング/モニタリングの将来の研究指向を強調する。
提案手法
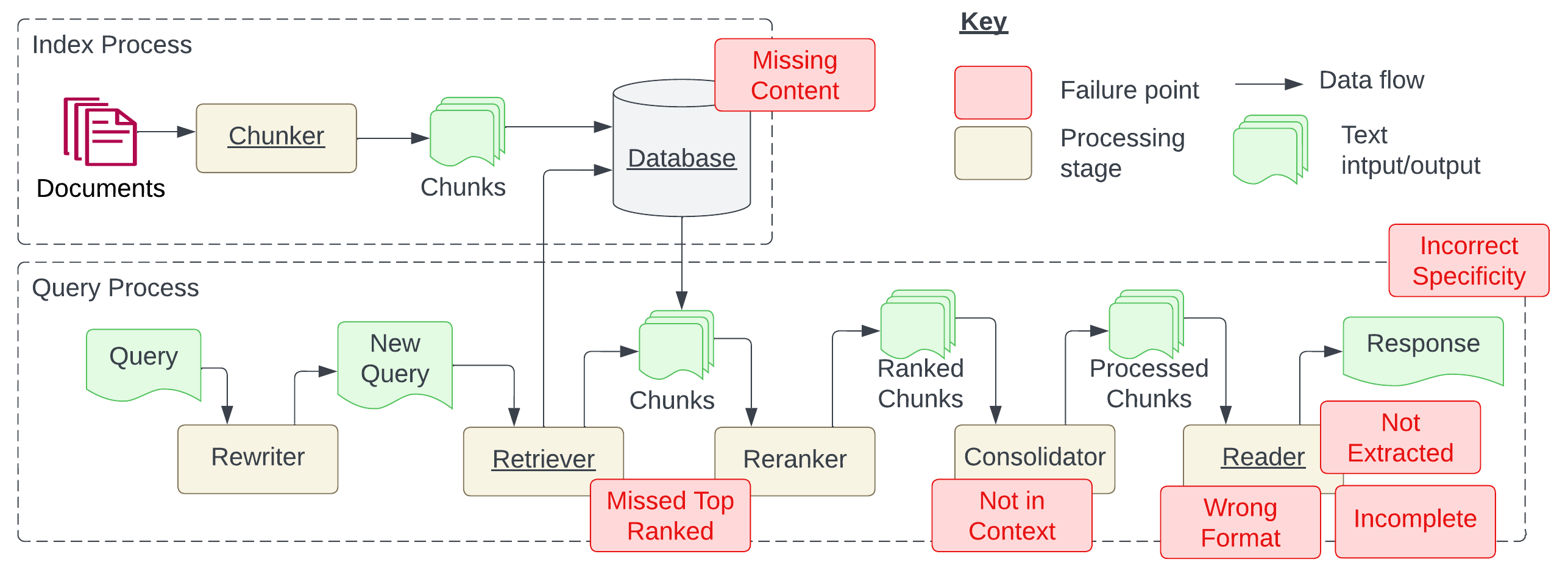
- RAGアーキテクチャとRAGパイプラインで使用されるインデックス作成とクエリ処理を説明する。
- 3つのケーススタディ(Cognitive Reviewer、AI Tutor、BioASQ)を実施し、実運用での障害点を観察する。
- 15,000件の文書と1,000のQ/Aペアを含むBioASQデータを用いて、GPT-4出力とOpenAI evalを通じて実証的に障害を特定する。
- ケーススタディ結果を分析し、7つの特定の障害点(FP1–FP7)を列挙し、教訓を導出する。
- 教訓を、障害点とケーススタディおよび潜在的な改善策を結ぶ表に要約する。
実験結果
リサーチクエスチョン
- RQ1RAGシステムを設計する際にどのような障害点が生じるか?
- RQ2頑健なRAGシステムを構築するうえで、経験的ケーススタディから生じる重要な留意点は何か?
- RQ3領域を超えてRAGの展開を改善する将来の研究方向は何か?
主な発見
- 七つの障害点が特定され、FP1からFP7とラベル付けされ、欠落した内容から不完全または誤形式の回答までを含む。
- BioASQを基にした実証的評価は15,000件の文書と1,000の質問を含み、誤りを指摘するためにOpenAI evalが用いられた。
- RAGシステムの検証は運用中のみ実施可能であり、頑健性は事前に完全設計されるのではなく進化する。
- 3つのケーススタディ(Cognitive Reviewer、AI Tutor、BioASQ)は領域特有の課題と実践的教訓を示す。
- 導入後もRAGの性能を維持するには継続的な較正とモニタリングが必要である。
- 本稿は障害点のカタログを提供し、チャンク化/埋め込み、finetuningとRAG、テスト/モニタリングの将来の研究方向を概説する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。