[論文レビュー] Sharing Knowledge in Multi-Task Deep Reinforcement Learning
この論文は、複数のRLタスク間で共有表現を学ぶことが、マルチタスクニューラルアーキテクチャと拡張AVI/API境界によってサンプル効率と性能を向上させることを理論的に正当化し、実証的に示している。
We study the benefit of sharing representations among tasks to enable the effective use of deep neural networks in Multi-Task Reinforcement Learning. We leverage the assumption that learning from different tasks, sharing common properties, is helpful to generalize the knowledge of them resulting in a more effective feature extraction compared to learning a single task. Intuitively, the resulting set of features offers performance benefits when used by Reinforcement Learning algorithms. We prove this by providing theoretical guarantees that highlight the conditions for which is convenient to share representations among tasks, extending the well-known finite-time bounds of Approximate Value-Iteration to the multi-task setting. In addition, we complement our analysis by proposing multi-task extensions of three Reinforcement Learning algorithms that we empirically evaluate on widely used Reinforcement Learning benchmarks showing significant improvements over the single-task counterparts in terms of sample efficiency and performance.
研究の動機と目的
- マルチタスク reinforcement learning (MTRL) におけるRLタスク間で表現を共有する利点を動機付け、形式化する。
- 有限時間のAVI/API境界をマルチタスク設定へ拡張することで理論的保証を提供する。
- 複数タスクの共通表現を学習するニューラルネットワークアーキテクチャを提案・検証し、それらのDRLベンチマーク上での実証性能を評価する。
提案手法
- ガウス複雑さとリプシッツ条件を用いて、近似的価値反復(AVI)および近似的政策反復(API)の境界のマルチタスク拡張を導出する。
- Maurer らの結果をマルチタスク設定に拡張し、共有表現がタスク数の増加とともに近似誤差をどのように低減するかを定量化する。
- タスク固有の入力ブロックと出力ブロック、および共有表現を備えたニューラルネットワークアーキテクチャを提案し、MFQI、MDQN、MDDPGを実現可能にする。
- MuJoCoおよびクラシックコントロールベンチマークで、FQI、DQN、DDPGのマルチタスク変種を実証的に評価する。
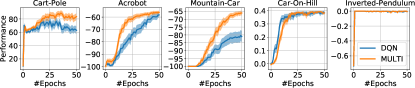
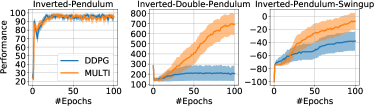
実験結果
リサーチクエスチョン
- RQ1どのような条件下で、複数のRLタスク間で表現を共有することが学習精度と収束を改善するのか?
- RQ2マルチタスク境界は深層ネットワークを用いたMTRLに対してAVI/API理論をどのように拡張するのか?
- RQ3標準的なRLベンチマークで、マルチタスクアーキテクチャは単一タスクの counterparts よりもサンプル効率と性能を向上させるのか?
主な発見
- 理論的境界は、マルチタスク設定において表現を共有することがAVI/APIの学習誤差を低減し得ることを示している。
- 共有表現アーキテクチャにより、MFQI、MDQN、MDDPGは複数のベンチマークで単一タスクのベースラインを上回る。
- Car-On-Hill、MuJoCoタスクおよびクラシックコントロール問題でサンプル効率と性能の改善を実証的に示している。
- マルチタスク手法は、事前学習済みの共有重みが新しいタスクの学習を改善する移転学習を促進する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。