[論文レビュー] Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Shikraは自然言語で空間座標を入力・出力できる統一マルチモーダルLLMで、Referential Dialogue(RD)を可能にし、追加モジュールなしでRDと従来のビジョン-言語タスクの両方に卓越します。
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at https://github.com/shikras/shikra.
研究の動機と目的
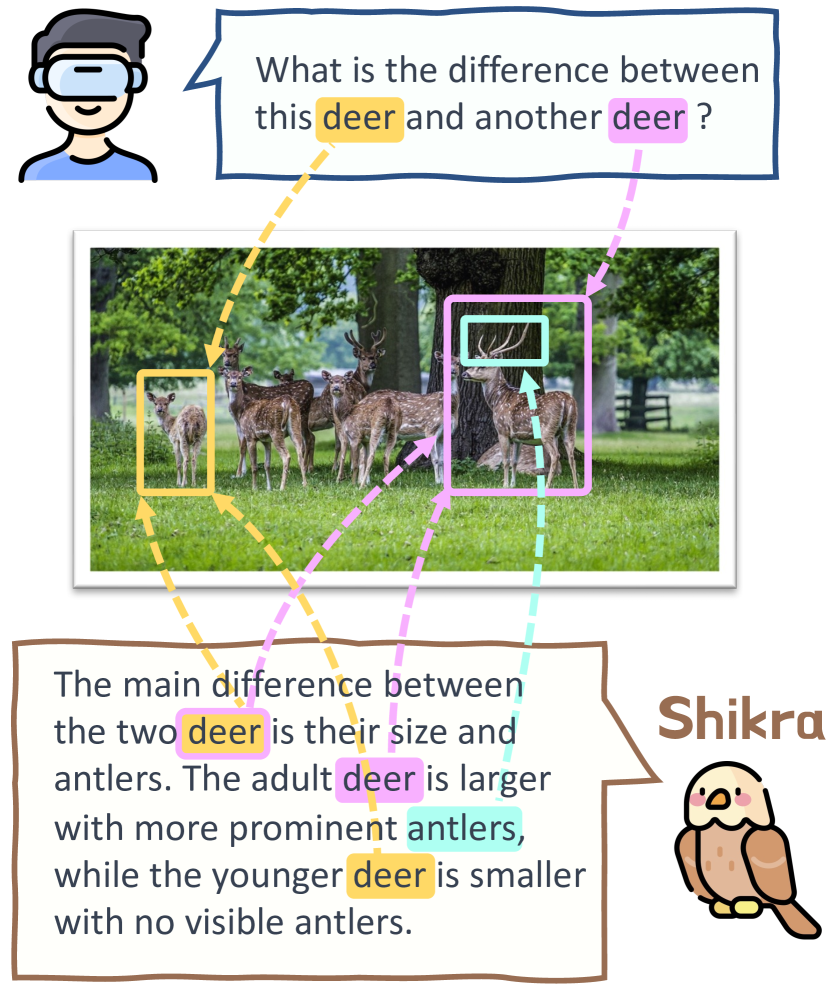
- MLLMsの中核能力としてReferential Dialogue (RD)を動機づけ、特定の画像領域について議論するために形式化する。
- Shikraを提案する。追加の語彙やプラグインを用意せず、自然言語で場所の入力/出力を処理する、シンプルで統一されたMLLM。
- RDが単一モデル内でREC、PointQA、VQA、Image Captioningといったタスクを可能にすることを示す。
- 位置注釈を用いた座標ベースの推論が、精度を向上させ、幻視(誤認知)を減らすことを示す。
提案手法
- 視覚エンコーダ(CLIPのViT-L/14)とLLM(Vicuna-7BまたはVicuna-13B)を用い、視覚特徴をLLMへ写像する1層の全結合層を用いる。
- すべての座標を文内トークンとして自然言語の数値で表現する。追加の位置エンコーダや専用語彙は導入しない。
- 位置注釈付きの、再編成されたVLデータとFlickr30K EntitiesをGPT-4経由で生成したShikra-RDデータで、二段階で学習する。
- 視覚エンコーダを固定したまま、AdamWとコサインアニーリングスケジューラを用いて8台のA100 GPU上でLLMをファインチューニングし、ステージ全体で約120時間。
実験結果
リサーチクエスチョン
- RQ1外部デテクターや語彙を用いずに、統一MLLMでReferential Dialogueを効果的に学習・一般化できるか?
- RQ2自然言語の数値位置表現は、局所化タスクにおいて座標語彙より十分で有利か?
- RQ3Shikraは従来のVLタスク(REC、PointQA、VQA、Captioning)において、タスク固有のチューニングなしでRDを実行できるか?
- RQ4位置注釈を用いた訓練は、視覚的幻視を減らし、グラウンディングを改善するか?
- RQ5標準のRD関連ベンチマークにおけるShikraの性能は、専門モデルやジェネラリストモデルと比較してどうか?
主な発見
- Shikraは微調整なしでRDと従来のVLタスクで有望な性能を示す。
- 座標はNL数字として入力/出力に自然に組み込まれ、追加の語彙なしで柔軟な空間推論を可能にする。
- 位置注釈(Grounding CoT)の使用は、通常のCoTより性能を改善し、制御された設定で幻視を減らす。
- 制御された比較において、REC様のタスクでは数値位置表現が座標語彙表現を上回る。
- Shikraは強力な PointQA 能力を達成し、VQAと画像キャプショニングで複数のベースラインと比較して競争力のある結果を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。