[論文レビュー] SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
SHViTは、メモリ効率の高いマクロ設計と単一ヘッド自己注意モジュールを導入し、GPU・CPU・モバイルデバイス全体で高速かつ高精度なビジョントランスフォーマを実現します。大きなストライドの16x16パッチステムとSHSAを用いた3段階アーキテクチャにより、タスク全体で速度と精度を最大化します。
Recently, efficient Vision Transformers have shown great performance with low latency on resource-constrained devices. Conventionally, they use 4x4 patch embeddings and a 4-stage structure at the macro level, while utilizing sophisticated attention with multi-head configuration at the micro level. This paper aims to address computational redundancy at all design levels in a memory-efficient manner. We discover that using larger-stride patchify stem not only reduces memory access costs but also achieves competitive performance by leveraging token representations with reduced spatial redundancy from the early stages. Furthermore, our preliminary analyses suggest that attention layers in the early stages can be substituted with convolutions, and several attention heads in the latter stages are computationally redundant. To handle this, we introduce a single-head attention module that inherently prevents head redundancy and simultaneously boosts accuracy by parallelly combining global and local information. Building upon our solutions, we introduce SHViT, a Single-Head Vision Transformer that obtains the state-of-the-art speed-accuracy tradeoff. For example, on ImageNet-1k, our SHViT-S4 is 3.3x, 8.1x, and 2.4x faster than MobileViTv2 x1.0 on GPU, CPU, and iPhone12 mobile device, respectively, while being 1.3% more accurate. For object detection and instance segmentation on MS COCO using Mask-RCNN head, our model achieves performance comparable to FastViT-SA12 while exhibiting 3.8x and 2.0x lower backbone latency on GPU and mobile device, respectively.
研究の動機と目的
- 効率的 ViT のマクロ設計とマイクロ設計における計算上の冗長性を特定する。
- メモリアクセスと待機時間を削減するためのメモリ効率の高いマクロ設計を提案する。
- マルチヘッドの冗長性を軽減するSingle-Head Self-Attention (SHSA)を開発する。
- 高速推論を維持しつつSHViTファミリを構築する。
- ImageNet分類とCOCO検出/セグメンテーションにおけるSHViTの有効性を示す。
提案手法
- 4x4パッチ埋め込みと比較して16x16パッチステム/3段階デザインのマクロ設計の冗長性を分析する。
- パッチifyステムを16x16にし、段階的なトークン削減を取り入れたメモリ効率の高いマクロ設計を提案する。
- Single-Head Self-Attention (SHSA)を導入し、単一のヘッドがチャネルのサブセットで動作し、他を残差として保持する。
- Depthwise Convolution、SHSA、FFNを組み合わせ、BNパススルーとReLU活性化を用いて高速化する。
- 大容量のチャネル数と重複するパッチ埋め込みを活用し、深さ/幅を変えた4つのSHViTバリアント(S1–S4)を訓練する。
- ImageNet-1Kでの分類とCOCOでのRetinaNet/Mask R-CNNを対象に、モバイル時延も評価する。
- SHViTを最先端の効率的モデルおよびONNX-runtimeパフォーマンスと比較する。
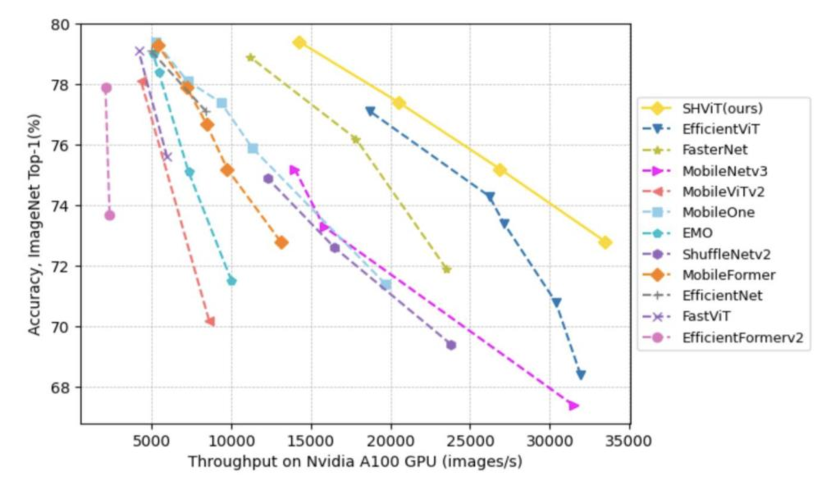
実験結果
リサーチクエスチョン
- RQ1より大きなストライドのパッチ埋め込みステムは、精度を保ちつつメモリアクセスコストを削減できるか。
- RQ2初期段階のアテンションを畳み込みで置換して、パフォーマンスを損なうことなく速度を向上できるか。
- RQ3後半のMHSA層におけるヘッド冗長性は顕著であり、単一ヘッド設計で軽減可能か。
- RQ4SHViTはデバイス(GPU、CPU、モバイル)とタスク(分類、検出、セグメンテーション)全般で、SOTAの効率的モデルと比較してどうなるか。
主な発見
- 16x16パッチステムと3段階設計は、4x4ステムと比較してメモリアクセスを削減しつつ競争力のある精度を維持する。
- 初期段階の畳み込みは、初期段階の効率性においてアテンションより優れる場合があり、待機時間を低減する。
- Single-Head Self-Attention (SHSA)は、チャネルセットの部分集合でアテンションを計算し、全チャネルへ最終投影を適用することでヘッドの冗長性とメモリバウンド操作を削減する。
- SHViTのバリアントは、GPU・CPU・モバイルデバイス全体で優れた速度-精度トレードオフを達成しており、例えばSHViT-S4は比較モデルに対してスループットとTop-1精度の顕著な向上を示す。
- COCOでは、SHViTバックボーンがRetinaNetおよびMask R-CNNヘッドで競争力のあるまたは優れたAP指標を、低遅延で提供する。
- ONNXランタイムは、SHViTのリシェイプとメモリバウンド操作の減少から恩恵を受け、リアルタイム性能を向上させる。
![Figure 2 : Macro design analysis. All stages are composed of MetaFormer blocks [ 28 ] . The stages depicted in blue and red utilize depthwise convolution and attention layers as token mixer, respectively. In the table below, the macro design numbers represent the number of channels, while the number](https://ar5iv.labs.arxiv.org/html/2401.16456/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。