[論文レビュー] SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore
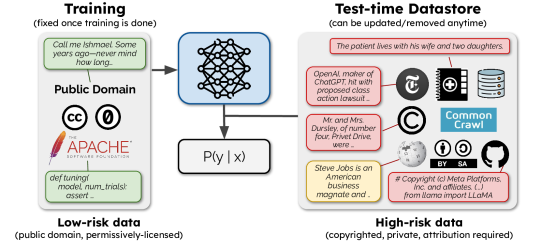
SILOはOpen License Corpusで訓練されたパラメトリックLMを、推論時に高リスクデータを含む非パラメトリック datastoreと組み合わせ、アトリビューションとオプトアウトを可能にし、datastoreを活用してドメイン外データでの性能ギャップを縮小する。
The legality of training language models (LMs) on copyrighted or otherwise restricted data is under intense debate. However, as we show, model performance significantly degrades if trained only on low-risk text (e.g., out-of-copyright books or government documents), due to its limited size and domain coverage. We present SILO, a new language model that manages this risk-performance tradeoff during inference. SILO is built by (1) training a parametric LM on Open License Corpus (OLC), a new corpus we curate with 228B tokens of public domain and permissively licensed text and (2) augmenting it with a more general and easily modifiable nonparametric datastore (e.g., containing copyrighted books or news) that is only queried during inference. The datastore allows use of high-risk data without training on it, supports sentence-level data attribution, and enables data producers to opt out from the model by removing content from the store. These capabilities can foster compliance with data-use regulations such as the fair use doctrine in the United States and the GDPR in the European Union. Our experiments show that the parametric LM struggles on domains not covered by OLC. However, access to the datastore greatly improves out of domain performance, closing 90% of the performance gap with an LM trained on the Pile, a more diverse corpus with mostly high-risk text. We also analyze which nonparametric approach works best, where the remaining errors lie, and how performance scales with datastore size. Our results suggest that it is possible to build high quality language models while mitigating their legal risk.
研究の動機と目的
- LMの訓練における法的リスクに対処するため、低リスクデータと高リスクデータを分離する
- 二つの構成要素モデルを開発する:許容的にライセンスされたテキストで訓練されたパラメトリックLMと推論時に使用する非パラメトリック datastore
- データの利用規制に合わせて文レベルのデータアトリビューションとデータのオプトアウトを可能にする
- datastore取得が高リスクデータを用いずに訓練なしで性能ギャップを埋められるか評価する
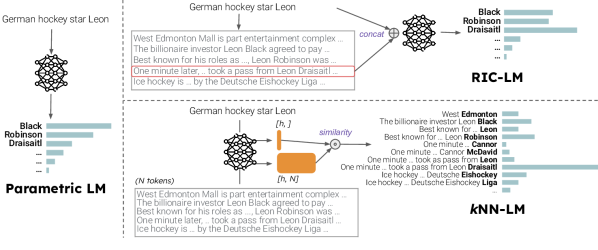
- ドメインシフト下で最も適した非パラメトリック手法(kNN-LM vs RIC-LM)を分析する
提案手法
- Open License Corpus (OLC)でライセンスサブセット(pd, sw, by)を変えて1.3BパラメータのLLaMAスタイルLMを訓練する
- 推論時にのみ照会される高リスクデータを含む推論時非パラメトリック datastoreを構築する
- 二つの取得手法を評価する:補間を用いたk最近傍LM (kNN-LM)と推論時文脈からの取得LM (RIC-LM)
- パラメトリックのみのSILOをPile訓練ベースラインのPythiaと14ドメインで perplexityの比較を行う
- datastoreベースのアトリビューションと例ごとのオプトアウトをデータ提供者に提供する
- datastoreのスケーリング効果とドメイン一般化への影響を分析する
実験結果
リサーチクエスチョン
- RQ1高リスクデータを含む非パラメトリック datastoreを訓練なしでLMの性能向上に寄与させられるか
- RQ2許容的に訓練されたパラメトリックLMと組み合わせた場合、kNN-LMとRIC-LMはドメインシフトを緩和する上でどう比較されるか
- RQ3 datastoreのサイズと取得手法がPileのようにより多様なデータで訓練されたモデルとの性能ギャップをどの程度埋められるか
- RQ4 datastoreが提供するアトリビューションとオプトアウトの能力はデータ利用規制の遵守をどのように支援するか
- RQ5著しく偏った許容ライセンスデータでの訓練による極端なドメイン一般化からどんな課題が生まれるか
主な発見
- Datastore強化されたSILOはパラメトリックのみのモデルと比較してドメイン外の性能を劇的に向上させる
- 平均してSILOはドメイン acrossでPythiaとの性能ギャップを約90%縮小する
- kNN-LMとRIC-LMの両方がドメイン外の困惑度を改善し、 datastoreのスケーリングから特にkNN-LMが恩恵を受ける
- kNN-LMの出力への直接的な影響とドメインシフトに対する頑健性がその優れた一般化を駆動する
- このアプローチは文レベルのアトリビューションと例ごとのオプトアウトを可能にし、データ利用規制の遵守を支援する
- datastoreサイズの拡大と非パラメトリック手法の洗練により性能をさらに向上させられる可能性がある
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。