[論文レビュー] Simple and Effective Masked Diffusion Language Models
SUBSパラメータ化と Rao-Blackwellized ELBO を用いたマスク付き拡散言語モデル(MDLM)は、言語ベンチマークにおける拡散モデルの新たなState-of-the-artを達成し、自己回帰的 perplexity に近づき、半自己回帰生成を用いた効率的な生成を実現する。
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/mdlm
研究の動機と目的
- 拡散モデルを離散言語データに適用する動機づけを行い、自己回帰モデルとの性能ギャップを埋める。
- 単純で効果的な MDLM フレームワークを、原理に基づくトレーニング目的とともに開発する。
- 改善されたトレーニングのために Rao-Blackwellized な連続時間 VAR lower bound を導出する。
- エンコーダ専用モデルの半自己回帰生成を含む、効率的なサンプリングを可能にする。
- MDLM フレームワークを DNA 配列などの非言語領域へ拡張し、生成能力を実証する。
提案手法
- トークン上にデータとマスクトークンの間を補間する離散フォワード拡散プロセスを定義する。
- SUBS:ゼロマスキング確率と持ち越しのアンマスクを強制する置換ベースのリバース拡散パラメータ化を導入する。
- 重み付き平均として簡略化される Rao-Blackwellized な連続時間 NELBO を導出する。
- 時刻条件付き拡散トランスフォーマーアーキテクチャ(DiT)と分散を減らすための低離散度サンプラーで訓練する。
- 祖先サンプリングによる高速推論と、ラウンド間でプレフィックスを再利用する半自己回帰(SAR)生成戦略を提供する。
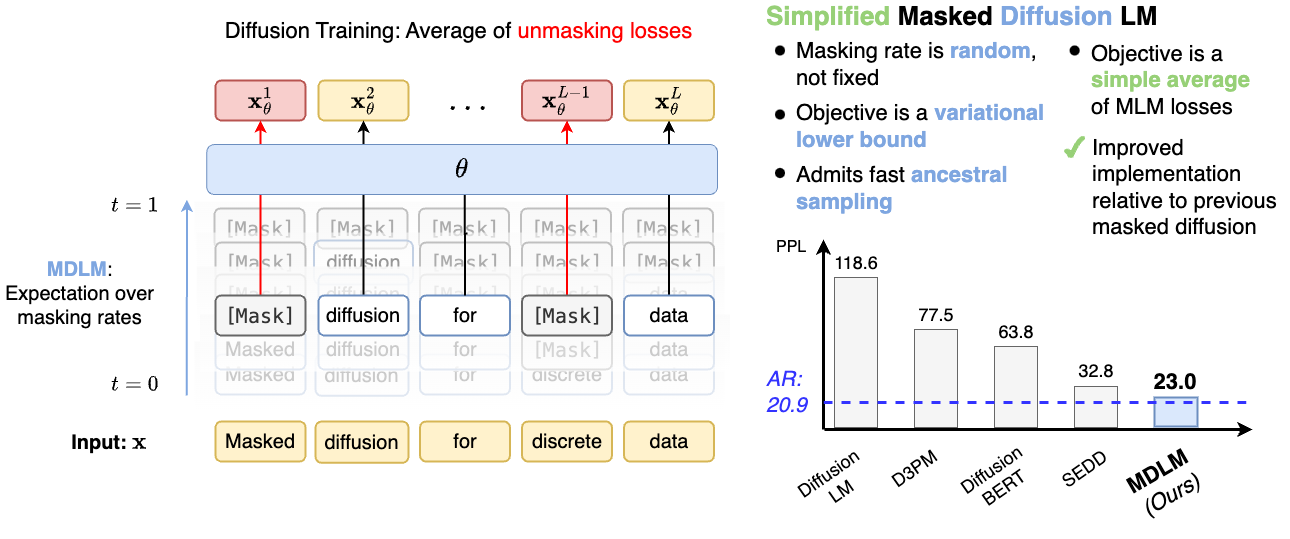
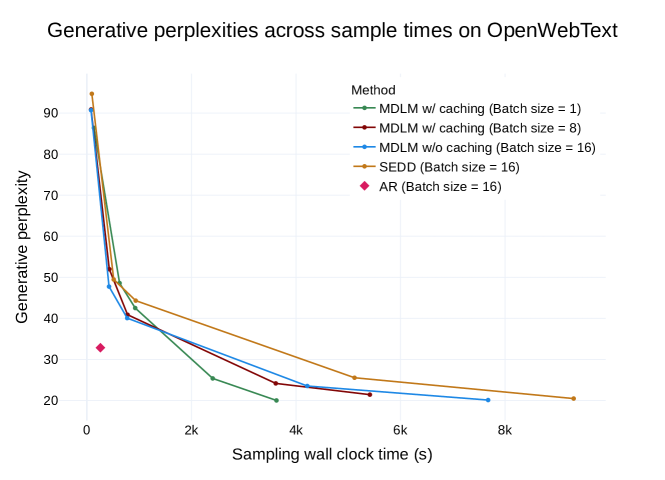
実験結果
リサーチクエスチョン
- RQ1効果的なトレーニングレシピを持つ masked 離散拡散は、標準的な言語モデリングベンチマークで従来の拡散モデルを上回るか。
- RQ2単純な SUBS パラメータ化は MDLM のより厳密で分散の小さい変分下限を生み出すか。
- RQ3エンコーダー専用 MDLM と効率的サンプラーは任意長のテキストを半自己回帰的に生成できるか。
- RQ4MDLM は下流タスクや DNA 配列のようなドメインのデータでどのような性能を示すか。
- RQ5トレーニングの選択、トークナイズ、アーキテクチャが AR モデルや従来の拡散法と比較して MDLM の性能に与える影響はどの程度か。
主な発見
- MDLM は LM1B および OWT ベンチマークで拡散モデルの新たな state-of-the-art を達成する。
- MDLM は自己回帰的 perplexity に近づき、AR モデルに対するギャップは設定に依存して相対的に 15–25% 減少する。
- SUBS パラメータ化と Rao-Blackwellized な連続時間 ELBO は尤度を改善し分散を低減する。
- SAR デコーディングはブロック自己回帰拡散ベースラインより高速な生成とより良い生成 perplexity を提供する。
- MDLM は DNA 配列モデリングで強力な生成能力と下流性能を示し、ファインチューニング時には GLUE の下流指標にも競争力を保つ。
- アブレーション研究は、キャリーオーバーのアンマスキングとゼロマスキング確率の重要性を性能向上の決定要因として示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。