[論文レビュー] Simple Contrastive Representation Learning for Time Series Forecasting
SimTSは history から future の潜在表現を予測することを学習し、negativeペアなしでベンチマーク全体にわたる多変量予測性能を強力に発揮する。時系列予測のための従来の対照学習仮定に挑戦する。
Contrastive learning methods have shown an impressive ability to learn meaningful representations for image or time series classification. However, these methods are less effective for time series forecasting, as optimization of instance discrimination is not directly applicable to predicting the future state from the historical context. To address these limitations, we propose SimTS, a simple representation learning approach for improving time series forecasting by learning to predict the future from the past in the latent space. SimTS exclusively uses positive pairs and does not depend on negative pairs or specific characteristics of a given time series. In addition, we show the shortcomings of the current contrastive learning framework used for time series forecasting through a detailed ablation study. Overall, our work suggests that SimTS is a promising alternative to other contrastive learning approaches for time series forecasting.
研究の動機と目的
- 予測のための対照学習におけるnegativeペアと强いデータ拡張の必要性を疑問視する。
- historyから未来の潜在表現を予測するシンプルなシアマ系フレームワークを提案する。
- history-to-futureの予測情報を最大化することが予測性能を多様な時系列データセットで改善することを示す。
- SimTSの堅牢性・汎用性を既存の対照法と比較して示す。
提案手法
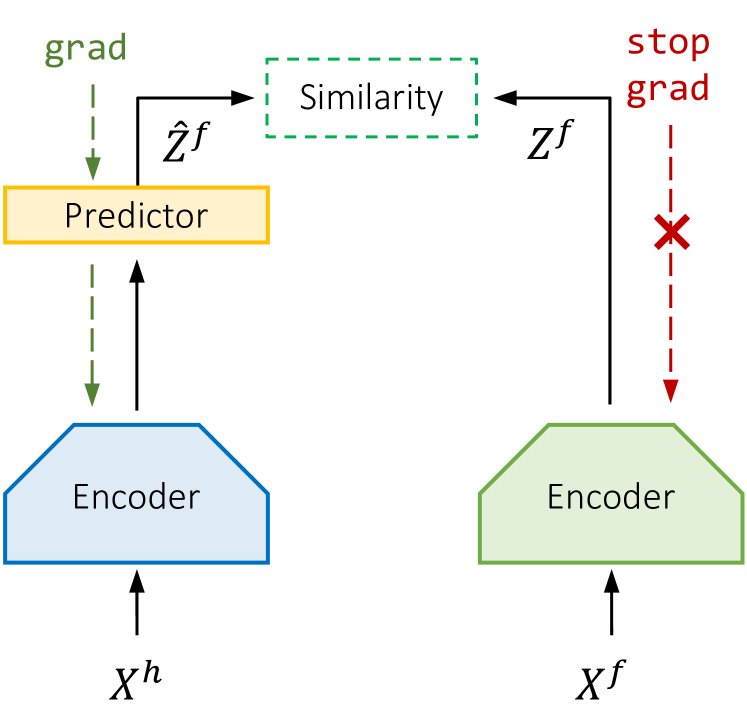
- シアマ系エンコーダF_thetaを用いて history X^h と future X^f を潜在表現Z^hとZ^fに写像する。
- history潜在表現から未来潜在表現を予測: ˜Z^f = G_phi(z^h_K) を、入力として歴史の最後の潜在列を使う予測器MLPで用いる。
- 予測された未来潜在表現 ˜_hat とエンコードされた未来 Z^f とのコサイン類似性損失で訓練する。Z^fにはエンコーダ崩壊を避けるためストップグラデントを適用する。
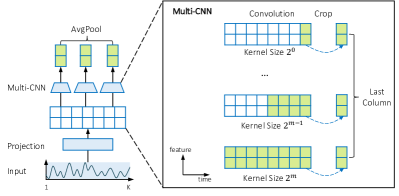
- 局所および全体の時間パターンを捉えるため、カーネルサイズ2^iのマルチスケール畳み込みエンコーダを用い、出力を平均化する。
- 負の例には依存しない。むしろ予測された未来とエンコードされた未来を正のペアとして扱い、予測の共有情報を最大化して予測性能を高める。
実験結果
リサーチクエスチョン
- RQ1 historyと未来の予測潜在表現マッチングが、時系列予測における従来の対照的インスタンス識別を凌ぐか?
- RQ2自己教師付き設定で予測を支えるアーキテクチャの選択(バックボーン、マルチスケールエンコーディング)と訓練機構(ストップグラデント)はどんな効果をもつか?
- RQ3負のサンプルとデータ拡張戦略は、対照ベースの時系列手法の予測性能にどのような影響を与えるか?
- RQ4SimTSは多様な一変量・多変量予測データセットに対して堅牢で汎用性があるか?
主な発見
- SimTSは最近の表現学習ベースの手法と比較して、複数の実世界の多変量データセットにおいて最先端または競合する予測性能を達成している。
- 負のサンプルを除去すると一般に性能が向上し、時系列対照学習における現在の負ペア構成の問題を浮き彫りにしている。
- 未来のエンコード経路に対するストップグラデントは最適な性能にとって重要であり、それを逆向きにするまたは除去すると結果が悪化する。
- マルチスケールカーネルを用いた畳み込みエンコーダは、この設定でTCNやLSTMバックボーンよりも高い性能を示す。
- アブレーション研究では、季節性・トレンドの分離仮定を緩めるとデータセットの定常性に応じて性能が影響を受けうることが示唆される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。