[論文レビュー] Simplifying Transformer Blocks
この論文は、スキップ接続、値/射影行列、逐次サブブロック、さらには正規化層を排除した簡易化トランスフォーマーブロック(SAS および SAS-P)を提案し、標準Pre-LNトランスフォーマーと同等またはそれを上回る訓練速度・スループットを達成しつつ、パラメータを最大約16%削減し、スループットを約15-16%向上させる。
A simple design recipe for deep Transformers is to compose identical building blocks. But standard transformer blocks are far from simple, interweaving attention and MLP sub-blocks with skip connections & normalisation layers in precise arrangements. This complexity leads to brittle architectures, where seemingly minor changes can significantly reduce training speed, or render models untrainable. In this work, we ask to what extent the standard transformer block can be simplified? Combining signal propagation theory and empirical observations, we motivate modifications that allow many block components to be removed with no loss of training speed, including skip connections, projection or value parameters, sequential sub-blocks and normalisation layers. In experiments on both autoregressive decoder-only and BERT encoder-only models, our simplified transformers emulate the per-update training speed and performance of standard transformers, while enjoying 15% faster training throughput, and using 15% fewer parameters.
研究の動機と目的
- 標準のトランスフォーマーブロックを訓練の不安定性とアーキテクチャの脆さのために簡略化の必要性を動機付ける。
- 訓練速度と性能にとって、どの成分(スキップ接続、値/射影行列、逐次サブブロック、正規化)が不可欠かを調査する。
- 信号伝播理論と実証的証拠に導かれた段階的に簡略化されたブロック variantsを開発する。
- 簡略化されたブロックが、自己回帰モデルとエンコーダーのみのモデルの両方において、標準のトランスフォーマーの訓練速度と性能に追従または上回ることを示す。
- さまざまな深さでの効率とスケーラビリティの向上を、GLUE 等の下流タスクで定量化する。
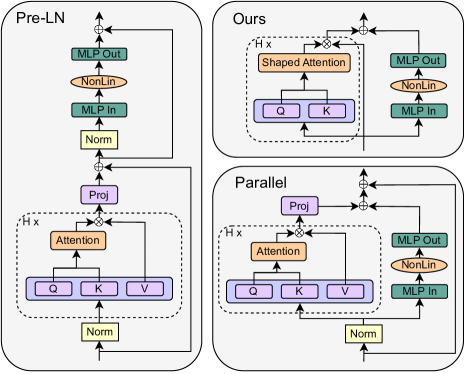
提案手法
- 信号伝播と実験に guided されて、Pre-LN トランスフォーマーブロックから要素を1つずつ削除する。
- 自己注意の値と射影行列を恒等行列に固定または削除して、1回の更新あたりの速度を回復する。
- 残差成分を再パラメータ化または重み付けを下げ、実際の skips なしでスキップ接続の利点を模倣する。
- 並列MHAおよびMLPサブブロックを採用して並列化を促進し、逐次依存性を減らす(SAS-P)。
- 正規化層を任意に削除し、その影響を評価する一方、SASおよびSAS-Pを正規化を含む main baseline として維持する。
- デコーダーのみのGPT様モデルとエンコーダーのみのBERT設定で評価し、GLUEファインチューニングを含め、Pre-LNのベースラインと比較する。
実験結果
リサーチクエスチョン
- RQ1標準のトランスフォーマーブロックの主要成分(スキップ接続、値/射影行列、逐次サブブロック、正規化)を削除して、更新ごとの訓練速度を損なわずに済むか。
- RQ2恒等初期化と特定の行列の拘束更新が、スキップレスの注意ブロックの速度低下を緩和できるか。
- RQ3並列化されたMHAとMLPブロック(並列ブロック)は、性能を維持しつつ訓練スループットを維持または向上できるか。
- RQ4簡略化されたブロックはより深いアーキテクチャに拡張でき、エンコーダーのみのモデルやGLUEのような下流タスクへ伝播するか。
主な発見
| Block | GLUE | Params | Speed |
|---|---|---|---|
| Pre-LN (Crammed) | 78.9 ± .7 | 120M | 1 |
| Parallel | 78.5 ± .6 | 120M | 1.05 |
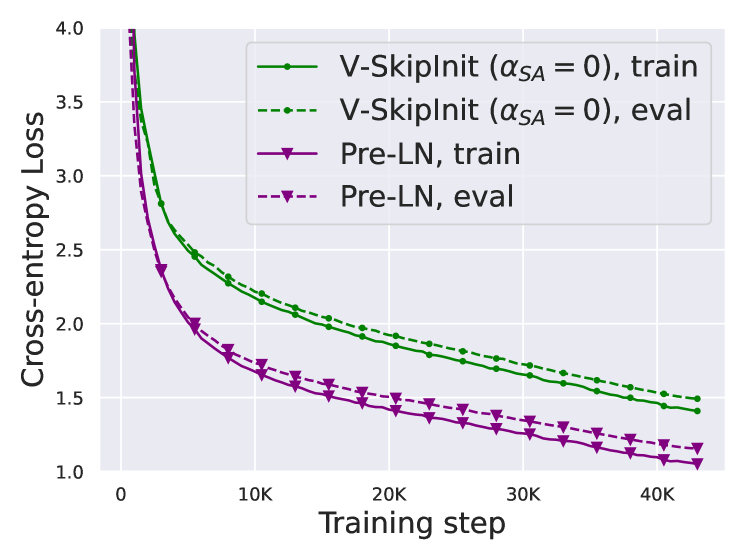
| V-SkipInit | 78.0 ± .3 | 120M | 0.95 |
| SAS (Sec. 4.2) | 78.4 ± .8 | 101M | 1.09 |
| SAS-P (Sec. 4.3) | 78.3 ± .4 | 101M | 1. |
- 注意サブブロックのスキップ接続は適切な初期化(Shaped Attention)とMLP経路の下方ウェイト付けで訓練速度を保持しつつ削除可能。
- 値と射影行列を恒等行列に固定または削除することで、1回の更新あたりの訓練速度を維持または改善し、パラメータとFLOPの大幅な削減を実現。
- MLPのスキップ接続を削除しても、並列サブブロックと組み合わせることでSAS-Pを実現し、Pre-LN訓練速度をより少ないパラメータで達成。
- SASおよびSAS-Pブロックは、実行時点でPre-LNの訓練速度に匹敵または上回り、パラメータを約13%削減、スループットを最大で約16%向上。
- 深さに応じたスケーリングは、簡略化ブロックがより深い構造で有利になることを示し、エンコーダーのみの設定(BERT)およびGLUEファインチューニングに拡張し、性能を維持。
- GLUEの結果は、SASおよびSAS-Pがパラメータ数を減らしスループットを高めつつベースライン性能に匹敵することを示す; V-SkipInit は1更新あたりの速度とスケーラビリティで遅れ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。