[論文レビュー] Simultaneously Localize, Segment and Rank the Camouflaged Objects
本論文は、識別的領域を局在化し、偽装物をセグメントし、偽装レベルをランク付けするジョイントモデルを紹介する。新しいCAM-FRデータセットと大規模テストセットNC4Kを背景に。
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
研究の動機と目的
- camouflage conspicuousness をモデリングして偽装と進化をより良く理解する動機付け。
- discriminative regions を局在化し、偽装物をセグメントするランク付けベースの COD フレームワークを提案する。
- localization、segmentation、ranking を支援する新しいデータセット(CAM-FR と NC4K)を提供する。
- fixation-based localization、segmentation、camouflage ranking を統合する triplet-task 学習モデルを開発する。
- quantitative および qualitative な結果を通じて COD の最先端の性能と解釈性を示す。
提案手法
- camouflage object ranking (COR) と camouflaged object localization (COL) を新しいタスクとして導入し、対応するアノテーションを作成する。
- eye-tracking に基づく fixation マップと検出遅延で既存の COD データセットを再ラベルして CAM-FR を localization および ranking のデータセットとする。
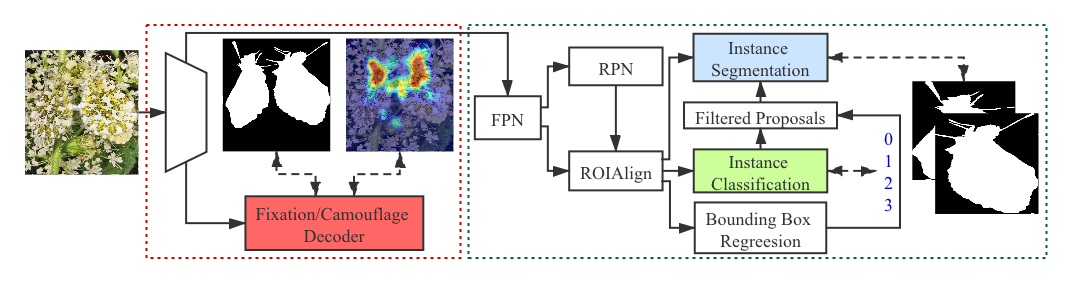
- backboneと dual residual attention (DRA) モジュールを用いて、 discriminative regions を局在化し camouflage をセグメントするための Fixation Decoder と Camouflage Decoder を備えたジョイントフレームワークを設計する。
- reverse attention 機構を組み込み、 discriminative regions から全体の camouflage へのセグメンテーションをガイドする。
- Ranking loss を用いて、 similarity prior S_p によって進行的な rank を反映させることができる、インスタンスセグメンテーションとランキング(camouflage level)を実行する Mask R-CNN ベースのパイプラインを拡張する。
実験結果
リサーチクエスチョン
- RQ1Can camouflaged objects be effectively localized and segmented while also ranking their level of camouflage?”,“Does incorporating fixation-based discriminative region localization improve COD performance?”,“How well does a joint framework perform CAM-FR tasks compared to task-specific models?”,“What is the impact of a prior on rank-label similarity in ranking camouflaged instances?”],
- RQ2key_findings_1_6List0/
- RQ3key_findings_2/
- RQ4key_findings_3/
- RQ5key_findings_4/
- RQ6key_findings_5/
- RQ7key_findings_6/
主な発見
| Method | S_alpha (CAMO) | F_beta_mean (CAMO) | E_mean (CAMO) | M (CAMO) | S_alpha (CHAMELEON) | F_beta_mean (CHAMELEON) | E_mean (CHAMELEON) | M (CHAMELEON) | S_alpha (COD10K) | F_beta_mean (COD10K) | E_mean (COD10K) | M (COD10K) | S_alpha (NC4K) | F_beta_mean (NC4K) | E_mean (NC4K) | M (NC4K) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours_cod_full | 0.793 | 0.725 | 0.826 | 0.085 | 0.893 | 0.839 | 0.938 | 0.033 | 0.793 | 0.685 | 0.868 | 0.041 | 0.839 | 0.779 | 0.883 | 0.053 |
- 提案手法 Ours は CAM-FR で学習させると COD ベンチマーク全体で競争力のある、または優れた結果を示し、識別局在化、偽装検出、ランキングを含む。
- 識別領域の局在化は偽装可視性を駆動する信頼できる領域を生み出し、 fixation に基づく指標で検証される。
- ランク付けコンポーネント(Ours_rank_new)は、 r_mae の ranking タスクでいくつかのベースライン(例: SOLOv2、MS-RCNN)を上回る。
- 統合的なジョイントフレームワークは識別領域の局在化と CAM ベース検出に利益をもたらし、3 つのタスクを共に訓練した場合に性能が向上することをアブレーションで示す。
- 著者は CAM-FR の訓練に加えて一般化を評価するための新しい大規模テストデータセット NC4K(4,121 枚の画像)を提供する。
![Figure 3: Overview of the joint fixation and segmentation prediction network. The first part indicates the pipeline that the Fixation Decoder and Camouflage Decoder generates the corresponding maps. The second part is the structrue of the decoders, where “ASPP” is the denseaspp module [ 57 ] . The t](https://ar5iv.labs.arxiv.org/html/2103.04011/assets/figures/joint_fix_camo_overview.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。