[論文レビュー] SingSong: Generating musical accompaniments from singing
SingSongは、ソース分離ペアで訓練された条件付き音声-genモデルとAudioLMの音声-音声生成への適応を通じて、入力ボーカルに合わせたインストゥルメンタルを生成します。孤立ボーカルへの一般化を改善し、リスナーの評価で強力なリトリーバル基準を上回るとされます。
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
研究の動機と目的
- 自分の歌唱テイストで伴奏を生成できることを通じて、直感的な音楽創作を動機づける。
- 訓練データ作成のために最先端のソース分離を活用して、対になるボーカル-インストゥルメンタルデータを作成する。
- 無条件音声生成モデル(AudioLM)を条件付きの音声-音声設定へ適応する。
- ソース分離された訓練データから実世界の孤立ボーカルへの一般化に対処する。
- 生成伴奏の知覚品質を評価し、忠実度と一貫性を高めるための指針を提供する。
提案手法
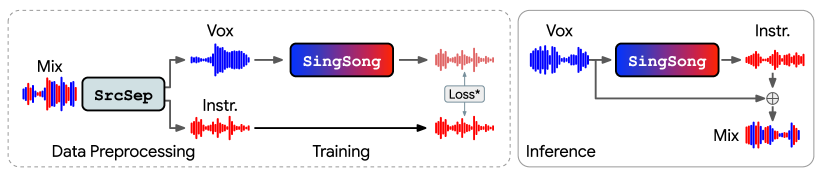
- 市販のソース分離アルゴリズムを適用して100万曲のペアデータを作成し、ボーカルとインストゥルメンタル源を整列させる。
- AudioLMを条件付きの音声-音声フレームワークに適応し、ボーカルを given して楽器音を生成する訓練を、ソース分離ペアで行う。
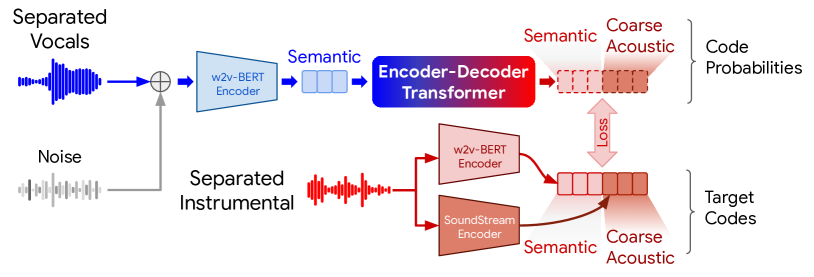
- 入力を表現する特徴量を検討し、ボーカル表現(意味情報と粗い音響コード)を探索し、源ノイズを導入して源アーティファクトを隠し generalization を向上させる。
- ボーカル特徴量から楽器の意味コードと粗い音響コードをマッピングするシーケンス対シーケンスモデル(T5ベースのエンコーダ-デコーダ)を訓練し、SoundStreamを介して波形へデコードする。
- 多段階の生成プロセスを用いる:ボーカル特徴量を条件として意味コードと粗いコードをサンプルし、粗い-to-細粒度の音響コードで洗練して波形再構成を行う;生成されたインストゥルメントを入力ボーカルと混合する。
- featurization戦略(Noisy、SA-SA、S-SA など)とモデルスケール(Base対XL)を試行して、孤立ボーカルへの一般化を最適化する。
実験結果
リサーチクエスチョン
- RQ1ボーカル入力を条件として、リアルタイムで一貫したインストゥルメンタル伴奏を生成できる generative model は存在するか。
- RQ2訓練データとしてソース分離データを用いることで、実世界の孤立ボーカルに対する音声-音声伴奏生成を効果的に実現できるか。
- RQ3ソース分離訓練データから孤立ボーカル入力へ最も一般化するボーカル条件化特徴は何か。
- RQ4モデル規模と特徴量設計の選択が、知覚品質と一般化ギャップにどのような影響を与えるか。
- RQ5SingSongは人間リスナーの音楽的適合性評価において、リトリーバルベースラインとどう異なるか。
主な発見
| Method | FAD_i | FAD_s | Delta |
|---|---|---|---|
| SA-SA | 3.01 | 1.61 | 1.39 |
| S-SA | 2.31 | 1.14 | 1.17 |
| SA-SA | 2.01 | 1.64 | 0.37 |
| A-A | 3.41 | 3.30 | 0.11 |
| SA-A | 2.81 | 1.87 | 0.95 |
| A-SA | 2.01 | 1.65 | 0.36 |
| S-SA | 1.36 | 1.17 | 0.19 |
| S-SA-XL | 1.28 | 0.96 | 0.32 |
- リスナーは同じボーカルに対して、SingSongのインストゥルメンタルを強力なリトリーバル基準より大幅に好評と判断した。
- 最良の構成(Noisy / S-SA)は孤立ボーカルへの一般化を大幅に改善(naive AudioLM適応と比較してFAD_iで相対55%改善)。
- より大きなモデル(SingSong-XL)へのスケーリングは、リスニングテストで基盤モデルを上回る知覚的改善をもたらした。
- ボーカルの粗い音響コードを conditioning から除外する(S-SA)や、ボーカルにノイズを追加することが一般化を改善し、訓練を安定化させた。
- インストゥルメンタルは、和声要素より打楽系/内容的一貫性が強い傾向があり、条件付けにおける和声的文脈の改善余地が示唆される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。