[論文レビュー] Skywork: A More Open Bilingual Foundation Model
Skywork-13B は 3.2T トークンで訓練されたバイリンガルの 13B LLM で、公開的にリリースされ、二段階の訓練 regime と強力な中国語言語モデリング、さらにオープンなベンチマークとデータを備える。
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
研究の動機と目的
- LLM 開発におけるオープンソースの透明性を促進するため、Skywork-13B と中間チェックポイントを公開する。
- 二段階の事前訓練パイプラインを提示する(一般用途の前訓練に続き、ドメイン特化の強化を適用)
- 多様な領域での中国語言語モデリングとベンチマーク性能の高さを実証する
- 再現性を確保するためのデータフィルタリングとコーパス構築の詳細を提供する
- データ汚染の懸念を強調し、漏洩検出手法を提案する
提案手法
- SkyPile を構築する。テキスト品質と分布を重視した大規模で公開可能な二言語対訳コーパス。
- 二段階の事前訓練:Stage-1 を SkyPile-Main で一般知識、Stage-2 を SkyPile-STEM を SkyPile-Main と混合してドメイン内 STEM 能力を注入。
- LLaMA に触発された Transformer-Decoder アーキテクチャを改変(RoPE、RMSNorm、前正規化、SwiGLU、FFN サイズの削減)。
- Megatron-LM を用いて 64 ノードの A800 クラスターで DP/PP/ZERO-1 を用いて訓練、効率化のため Flash Attention V2 を利用。
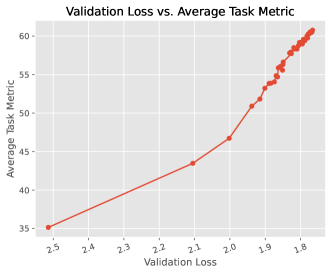
- 複数の保持セットを用いた横断的な検証損失で訓練進行をモニタリングし、単一の訓練損失や単一ベンチマークだけに依らない評価を重視。
- 再現性を支援するため、150B+ トークンのオープン中国語コーパス断片(SkyPile-150B)と中間チェックポイントを公開する。
実験結果
リサーチクエスチョン
- RQ1二段階で公開的に訓練されたバイリンガル LLM は、同程度のサイズの同僚と比較して一般言語モデリングおよびドメイン固有タスクでどのような性能を示すか?
- RQ2ドメイン内(STEM)連続事前訓練が中国語および全体の STEM タスク性能に及ぼす影響はどのようなものか?
- RQ3多領域検証損失を用いた能動的モニタリングは事前訓練中の下流性能の信頼できる指標となり得るか?
- RQ4RoPE、RMSNorm、SwiGLU、FFN サイズといったアーキテクチャ選択・ハイパーパラメータがモデル性能に与える影響は何か?
- RQ5大規模オープンコーパスにおけるデータ汚染・漏洩リスクは何で、それを検出するにはどうするべきか?
主な発見
| モデル | CEVAL | CMMLU | MMLU | GSM8K |
|---|---|---|---|---|
| OpenLLaMA-13B | 27.1 | 26.7 | 42.7 | 12.4 |
| LLaMA-13B | 35.5 | 31.2 | 46.9 | 17.8 |
| LLaMA2-13B | 36.5 | 36.6 | 54.8 | 28.7 |
| Baichuan-13B | 52.4 | 55.3 | 51.6 | 26.6 |
| Baichuan2-13B | 58.1 | 62.0 | 59.2 | 52.8 |
| XVERSE-13B | 54.7 | - | 55.1 | - |
| InternLM-20B | 58.8 | - | 62.0 | 52.6 |
| Skywork-13B | 60.6 | 61.8 | 62.1 | 55.8 |
- Skywork-13B はオープン13Bモデルの中で CEVAL(60.6)と MMLU(62.1)のベンチマークでリーディング結果を達成。
- Skywork-13B は GSM8K で 55.8 を達成し、同程度のサイズのいくつかのオープンモデルを上回る。
- CMMLU では Baichuan2-13B がトップ(62.0)を獲得する一方で、Skywork-13B も依然として高い性能(61.8)を示す。
- 言語モデリング Domain 評価では、Skywork-13B が 技術(11.58)、映画(21.84)、政府(4.76)、金融(4.92)など多様な領域を横断して最も低い平均困惑度(9.42)を達成。
- ステージ2 の STEM 重視の事前訓練は STEM 関連の能力とベンチマークを大幅に強化(例:CEVAL、GSM8K)し、言語モデリングの安定性を崩さない。
- Skywork-13B は中国語モデリングの強力さを際立たせ、多くのオープンモデルや巨大なクローズドモデルをも凌駕する中国語中心のベンチマークで卓越した性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。