[論文レビュー] Small Language Models: Survey, Measurements, and Insights
本論文は、59のオープンソースデコーダーのみの小規模言語モデル(100M–5B)を調査し、アーキテクチャ、トレーニングデータ、アルゴリズム、能力、およびエッジ展開の洞察を得るためのデバイス上の実行コストをベンチマークします。
Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 70 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, mathematics, in-context learning, and long context. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.
研究の動機と目的
- デコーダー専用の小規模言語モデル(100M–5B)とそのリリース構成を体系的にレビューする。
- 調査対象となるSLMのアーキテクチャ、トレーニングデータセット、およびトレーニングアルゴリズムを分析する。
- 常識的推論、インコンテキスト学習、数学、コーディングにおける能力をベンチマークする。
- エッジ展開のために、デバイス上の実行コスト(待機時間、メモリ、エネルギー)を評価する。
- 将来のSLM研究とハードウェア配慮設計への洞察と指針を提供する。
提案手法
- 100M–5Bパラメータを持つ59個のオープンソースデコーダー専用SLMsを収集・分類する。
- 常識的推論、問題解決、数学、インコンテキスト学習における能力をベンチマークする。
- 共通推論エンジン(llama.cpp)を使用して、エッジデバイス上のデバイス上の実行コスト(プリフィル待機時間、デコード待機時間、メモリ、エネルギー)を測定する。
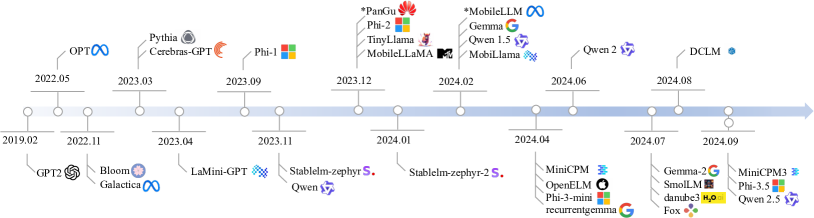
- アーキテクチャ(アテンションタイプ、FFN、活性化関数、正規化、語彙)とトレーニングデータの使用状況を分析する。
- トレーニングデータセットとデータ品質を比較し、モデルベースのデータフィルタリングを含む。
- SLM開発におけるデータ品質、データセット選択、アーキテクチャ選択について洞察を抽出する。
実験結果
リサーチクエスチョン
- RQ1SLMにおいて一般的なアーキテクチャの選択は何で、それはデバイス上のパフォーマンスにどのように影響するか?
- RQ2オープンソースのトレーニングデータセットとデータ品質は、クローズドソースのデータと比較してSLMの能力にどう影響するか?
- RQ3SLMsは常識的推論、問題解決、数学タスクでどのように性能を示し、モデルサイズとデータがこの性能にどう影響するか?
- RQ4SLMのハードウェアと量子化設定を横断したデバイス上の待機時間、メモリ、エネルギー特性は何か?
主な発見
- SLMsは2022年から2024年にかけて、常識的推論、問題解決、数学の各分野でかなりの性能向上を示す(それぞれ約10.4%、13.5%、13.5%)。
- Phiファミリーはほとんどのタスクで最先端の結果を提供し、Phi-3-miniは一部のケースでLlama 3.1 8Bに互換し、評価対象モデルの中では数学でPhi-3-miniが首位。
- モデルベースのフィルタリングを採用するFineWeb-EduやDCLM-baselineのようなオープンソースデータセットは、クローズドデータセットと比較して競争力のある性能を達成。
- パラメータ数が大きいほど一般に性能は向上するが、例外も存在(例:Qwen 2)。データ品質とトレーニングデータの選択が単なるモデルサイズを上回ることが多い。
- インコンテキスト学習は一般に大規模モデルで恩恵を受け、平均して5ショットプロンプトは約2.1%の精度向上をもたらし、Gemma-2が最大の利得を示した。
- 複雑な推論や数学を要するタスクにおいて、オープンソースとクローズドソースのモデル間には依然としてギャップがあり、高品質な推論データセットの必要性を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。