[論文レビュー] SnapKV: LLM Knows What You are Looking for Before Generation
SnapKV は、観察ウィンドウからヘッドごとの重要な注意特徴を特定・クラスタリングするチューニング不要のKVキャッシュ圧縮手法で、長い文脈のLLMタスクにおいてデコードを高速化し、メモリ使用量を低減しつつ、精度は同程度を保つ。
Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an 'observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to the baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to the baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
研究の動機と目的
- 生成中にプロンプトトークンへの注意が一貫したパターンに従うかを調査する。
- 性能を犠牲にせず、プロンプト KV サイズを削減する KV キャッシュ圧縮手法を開発する。
- ヘッドごとの特徴クラスタリングが長い文脈処理を効率化しつつ、重要な情報を保持できることを示す。
- 複数のLLMや長文コンテキストのベンチマークで SnapKV を評価し、速度とメモリの利得を確立する。
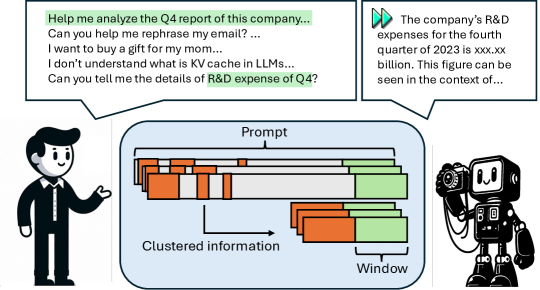
提案手法
- 観察ウィンドウを用いて一貫した重要な KV ポジションを特定するために、プロンプトからプレフィックスへのアテンションを分析する。
- アテンションウェイトを投票・集約して、ヘッドごとに上位K個の重要なポジションを選択する(プールされたウェイトのTop-k)。
- 1Dプーリング(kernel_size)を適用して、細粒度圧縮のために近接する重要なポジションをクラスタリングする。
- 生成のための改訂KVキャッシュを格納する前に、選択された特徴を観察ウィンドウと連結する。
- 一般的なフレームワークと統合する実用的で最小限のコード実装の SnapKV を提供する。
- 長文脈データセットとモデルを横断して精度と効率を評価し、並列デコードとの互換性をテストする。
実験結果
リサーチクエスチョン
- RQ1生成文脈全体でプロンプトトークンに割り当てられるアテンションに一貫したパターンはあるか。
- RQ2プロンプト長、指示の位置、タスクタイプは、特定された重要な KV 特徴にどのように影響するか?
- RQ3文脈認識型 KV 圧縮は、KVキャッシュサイズを劇的に削減しつつ生成品質を維持できるか?
主な発見
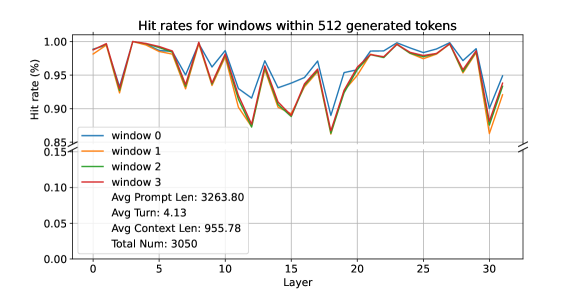
- 特定のプロンプトキーへのアテンション割り当ては、生成時に文脈を超えて著しく一貫している。
- 指示の配置(文脈の前か後か)は高いヒット率をもたらし、異なる指示は重要と見なされるプレフィックスキーを変える。
- プーリングに基づくクラスタリングは、KV圧縮におけるナイーブなTop-K選択よりも検索精度を向上させる。
- SnapKV は、16Kトークン入力に対してベースラインと比較してデコードを3.6倍高速化し、メモリ効率を8.2倍向上させる。
- SnapKV は、Needle-in-a-Haystack テストでほとんど精度低下なしで、単一の A100-80GB GPU 上で最大380K コンテキスト・トークンを処理可能。
- LongBench では、プロンプトKVキャッシュを1024/2048/4096トークンに圧縮しても性能低下はほとんどなく、1024で平均92%圧縮、4096で68%圧縮。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。