[論文レビュー] Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning
tldr: 本論文は、counterfactual reasoningを用いてエージェントが他者へ因果的に影響を及ぼす程度を測定し、中央集権的な訓練なしに協調実現のための意味ある emergent communication を可能にする、MARL の社会的影響内在報酬を導入する。
We propose a unified mechanism for achieving coordination and communication in Multi-Agent Reinforcement Learning (MARL), through rewarding agents for having causal influence over other agents' actions. Causal influence is assessed using counterfactual reasoning. At each timestep, an agent simulates alternate actions that it could have taken, and computes their effect on the behavior of other agents. Actions that lead to bigger changes in other agents' behavior are considered influential and are rewarded. We show that this is equivalent to rewarding agents for having high mutual information between their actions. Empirical results demonstrate that influence leads to enhanced coordination and communication in challenging social dilemma environments, dramatically increasing the learning curves of the deep RL agents, and leading to more meaningful learned communication protocols. The influence rewards for all agents can be computed in a decentralized way by enabling agents to learn a model of other agents using deep neural networks. In contrast, key previous works on emergent communication in the MARL setting were unable to learn diverse policies in a decentralized manner and had to resort to centralized training. Consequently, the influence reward opens up a window of new opportunities for research in this area.
研究の動機と目的
- 協調とコミュニケーションを内在報酬に基づく社会的影響で促進する。
- 因果影響を反事実推論を用いて定義・計算し、他者への影響を定量化する。
- 影響報酬がエージェントの行動間の相互情報量を最大化することと協調を促進することと一致することを示す。
- MOA(Model of Other Agents)を用いた内部モデルを介して独立訓練を可能にし、それでも協調を達成できることを示す。
提案手法
- 反事実アクションを用いてエージェントが他のエージェントの行動分布をどれだけ変えるかを定量化する intrinsic influence reward を定義する。
- 影響報酬をエージェントの行動間の相互情報量と関連付け、協調の改善を実証的に検証する。
- 影響報酬に導かれる明示的な通信チャネルを含むフレームワークを拡張し、 emergent communication の質を評価する。
- 中央集権的アクセスなしに影響を計算できる MOA(Model of Other Agents)を導入する。
- ピクセルからのエンドツーエンド学習をリカレントアーキテクチャと A3C 系のアップデートで行い、影響重みのカリキュラム学習を行う。
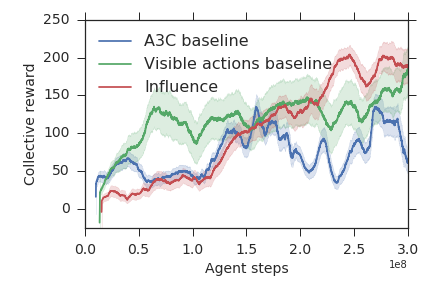
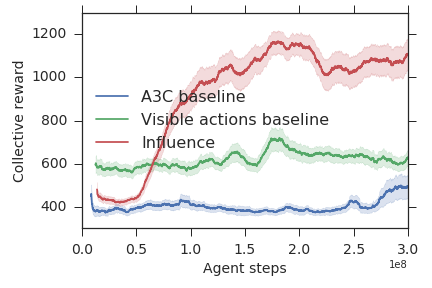
実験結果
リサーチクエスチョン
- RQ1因果影響に基づく intrinsic reward は中央訓練なしでマルチエージェント環境の協調を改善できるか?
- RQ2エージェント間の因果影響を最大化することはより意味のある emergent communication につながるか?
- RQ3MOA を備えたエージェントは独立して訓練でき、それでも協調行動を達成できるか?
- RQ4影響報酬は実際にエージェントの行動間の相互情報量を最大化することに関連しているか?
主な発見
- 社会的影響報酬で訓練したエージェントは、Sequential Social Dilemmas (SSDs) においてベースラインおよび欠陥カ所のエージェントより高い集合報酬を達成する。
- 影響を用いた通信は学習の高速化と集合報酬の向上をもたらし、より意味のある協調的なメッセージングを促す。
- MOA を用いるエージェントは内部的に影響を計算でき、中央集権的なコントローラなしに協調を達成し、ベースラインを上回る。
- 通信によって影響を受けることと個別報酬を高く受け取ることの間に有意な相関があり、情報的な通信を支持する。
- 影響メカニズムはエージェントの行動間に明示的な依存関係を作ることにより、大規模な MARL 設定で勾配分散を減少させる。
- 影響メカニズムは聴き手の環境報酬と整合する自発的な emergent communication を誘発し、協力を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。