[論文レビュー] SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes
SOD-YOLOv8 は Efficient GFPN ベースのマルチスケール融合、C2f-EMA アテンションモジュール、追加の高解像度検出層、PIoU ロスを用いて、交通シーンでの小さな物体検出を向上させつつ大きなレイテンシ増を抑える。
Object detection as part of computer vision can be crucial for traffic management, emergency response, autonomous vehicles, and smart cities. Despite significant advances in object detection, detecting small objects in images captured by distant cameras remains challenging due to their size, distance from the camera, varied shapes, and cluttered backgrounds. To address these challenges, we propose Small Object Detection YOLOv8 (SOD-YOLOv8), a novel model specifically designed for scenarios involving numerous small objects. Inspired by Efficient Generalized Feature Pyramid Networks (GFPN), we enhance multi-path fusion within YOLOv8 to integrate features across different levels, preserving details from shallower layers and improving small object detection accuracy. Also, A fourth detection layer is added to leverage high-resolution spatial information effectively. The Efficient Multi-Scale Attention Module (EMA) in the C2f-EMA module enhances feature extraction by redistributing weights and prioritizing relevant features. We introduce Powerful-IoU (PIoU) as a replacement for CIoU, focusing on moderate-quality anchor boxes and adding a penalty based on differences between predicted and ground truth bounding box corners. This approach simplifies calculations, speeds up convergence, and enhances detection accuracy. SOD-YOLOv8 significantly improves small object detection, surpassing widely used models in various metrics, without substantially increasing computational cost or latency compared to YOLOv8s. Specifically, it increases recall from 40.1\% to 43.9\%, precision from 51.2\% to 53.9\%, $ ext{mAP}_{0.5}$ from 40.6\% to 45.1\%, and $ ext{mAP}_{0.5:0.95}$ from 24\% to 26.6\%. In dynamic real-world traffic scenes, SOD-YOLOv8 demonstrated notable improvements in diverse conditions, proving its reliability and effectiveness in detecting small objects even in challenging environments.
研究の動機と目的
- 交通シーンと UAV 画像における小物体検出の課題に対処する。
- 小物体のために浅層の空間情報を保持する特徴融合を改善する。
- チャンネル間の重みを再配分するアテンションベースの C2f-EMA モジュールを導入する。
- Bounding box 回帰と収束を改善するために Powerful-IoU (PIoU) を導入する。
- YOLOv8 および他のベースラインと比較して、実世界の交通画像データでの性能を評価する。
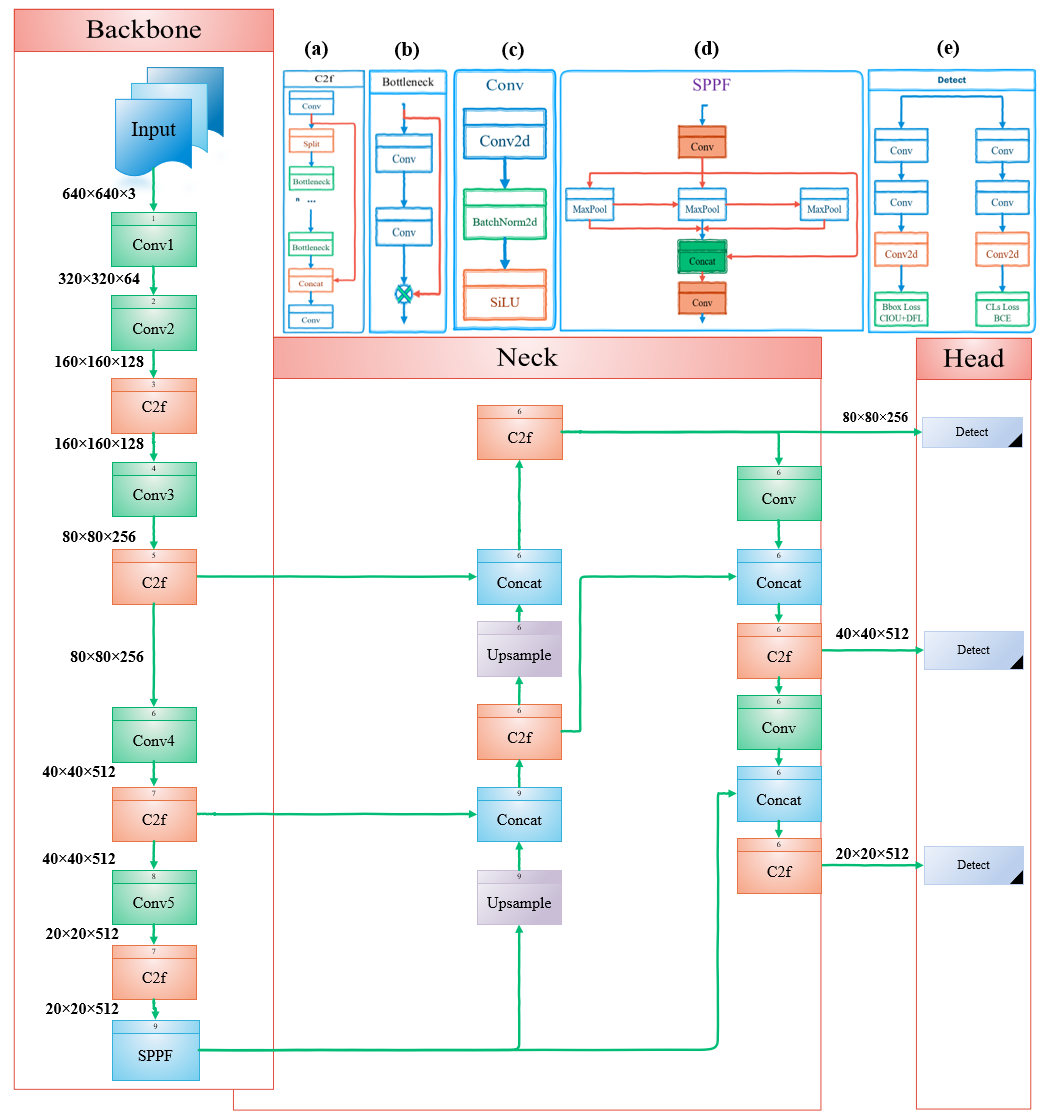
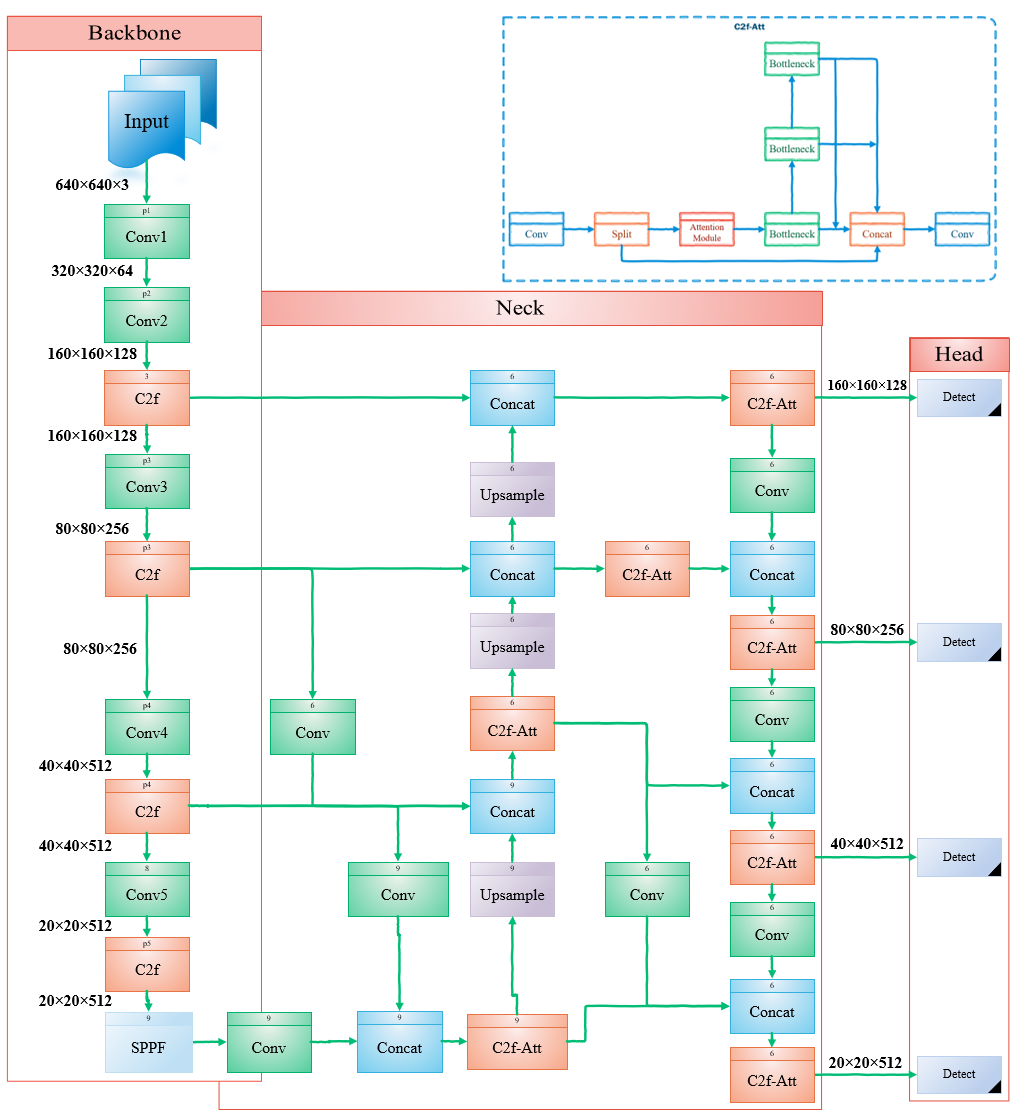
提案手法
- PAFPN を Efficient-RepGFPN に触発された強化 GFPN に置換し、スキップ層および queen fusion コネクションを用いたマルチスケール特徴融合を改善する。
- P2 特徴を取り入れて第四の検出層を追加し、小物体の高解像度空間情報を保持する。
- C2f を置き換えた C2f-EMA を導入し、 Efficient Multi-Scale Attention を用いてチャネルごとの重みを再分配し、小物体表現を改善する。
- CIoU を回帰損失で PIoU に置換し、収束を加速し局所化の安定性を向上させる。
- 1×1 および 3×3 ブランチと 2D 空間注意処理を含む EMA ベースの C2f-EMA メカニズムの詳述を提供する。
- 視覚分析および実世界の交通画像を通じて、方法がレイテンシの大幅な増加なく小物体検出を改善することを示す。
実験結果
リサーチクエスチョン
- RQ1YOLOv8 における小物体に重要な浅層の空間情報を保持するよう、マルチスケール特徴融合をどのように再設計できるか。
- RQ2C2f-EMA アテンションモジュールは、YOLOv8 ネックにおける小物体検出性能と特徴表現を改善するか。
- RQ3PIoU は moderate-quality アンカー上で CIoU より高速な収束とより良い境界ボックス回帰を提供するか。
- RQ4高解像度特徴を活用する第四の検出層を追加することは、小物体検出精度とレイテンシにどのような影響を与えるか。
- RQ5SOD-YOLOv8 は、ベースライン YOLOv8s および他の小物体検出器と比較して、現実世界の動的な traffic シーンでどの程度性能を発揮するか。
主な発見
- Recall が 40.1% から 43.9% に改善。
- Precision が 51.2% から 53.9% に改善。
- mAP@0.5 が 40.6% から 45.1% に改善。
- mAP@0.5:0.95 が 24% から 26.6% に改善。
- SOD-YOLOv8 は YOLOv8s と比較してレイテンシと計算コストの変化を控えめに抑えつつ、これらの改善を達成。
- 視覚分析と実世界の交通画像は、様々な条件下での小物体検出の改善を検証。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。