[論文レビュー] SOEN-101: Code Generation by Emulating Software Process Models Using Large Language Model Agents
LCG はマルチエージェント LLM を用いて Waterfall、TDD、Scrum のプロセスをコード生成にエミュレートする; Scrum ベースの LCG は Pass@1 の最大の向上を達成し、モデルのバリエーション間でより安定した結果を示す。
Software process models are essential to facilitate collaboration and communication among software teams to solve complex development tasks. Inspired by these software engineering practices, we present FlowGen - a code generation framework that emulates software process models based on multiple Large Language Model (LLM) agents. We emulate three process models, FlowGenWaterfall, FlowGenTDD, and FlowGenScrum, by assigning LLM agents to embody roles (i.e., requirement engineer, architect, developer, tester, and scrum master) that correspond to everyday development activities and organize their communication patterns. The agents work collaboratively using chain-of-thought and prompt composition with continuous self-refinement to improve the code quality. We use GPT3.5 as our underlying LLM and several baselines (RawGPT, CodeT, Reflexion) to evaluate code generation on four benchmarks: HumanEval, HumanEval-ET, MBPP, and MBPP-ET. Our findings show that FlowGenScrum excels compared to other process models, achieving a Pass@1 of 75.2, 65.5, 82.5, and 56.7 in HumanEval, HumanEval-ET, MBPP, and MBPP-ET, respectively (an average of 15% improvement over RawGPT). Compared with other state-of-the-art techniques, FlowGenScrum achieves a higher Pass@1 in MBPP compared to CodeT, with both outperforming Reflexion. Notably, integrating CodeT into FlowGenScrum resulted in statistically significant improvements, achieving the highest Pass@1 scores. Our analysis also reveals that the development activities impacted code smell and exception handling differently, with design and code review adding more exception handling and reducing code smells. Finally, FlowGen models maintain stable Pass@1 scores across GPT3.5 versions and temperature values, highlighting the effectiveness of software process models in enhancing the quality and stability of LLM-generated code.
研究の動機と目的
- ソフトウェア開発をマルチエージェントプロセスとしてモデル化する動機づけを行い、コード品質と信頼性を向上させる。
- コード生成のために Waterfall、TDD、Scrum をエミュレートするエージェントベースのフレームワークである LCG を提案する。
- 開発活動とプロセスモデルがコード正確性とコードスメルに与える影響を調査する。
- LLM モデルバージョンと温度設定を横断した安定性を評価する。
提案手法
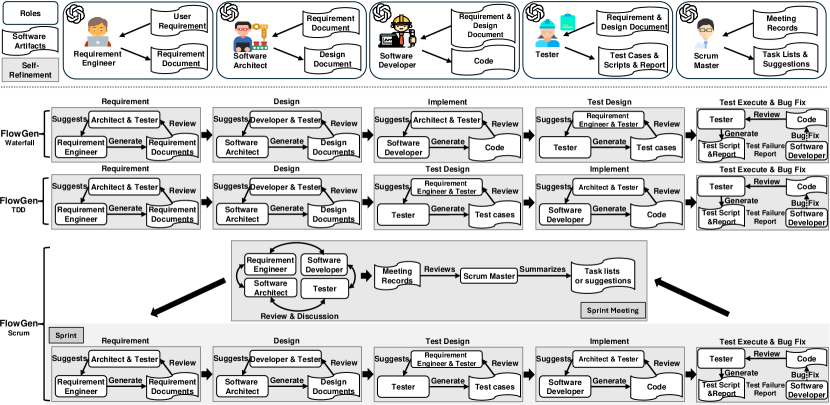
- 要件エンジニア、アーキテクト、デベロッパー、テスター(Scrum では Scrum Master)などの開発役割を LLM エージェントとして定義する。
- Waterfall(有序)、TDD(実装前にテストを行う有序)、Scrum(スプリントのような会議を含む無秩序)に対応する三つの対話パターンを実装する。
- 思考過程の推論、プロンプトの構成、自己改良を適用して成果物を反復的に改善する。
- 四つのベンチマーク(HumanEval、HumanEval-ET、MBPP、MBPP-ET)でゼロショットプロンプトを用いて評価し、Pass@1 を主要指標とする。
- 同一条件下でGPT-3.5ベースライン(GPT)と比較し、コードスメルと例外処理を分析する。
実験結果
リサーチクエスチョン
- RQ1Waterfall、TDD、Scrum などの異なるソフトウェアプロセスモデルをエミュレートすることが、GPTベースラインと比較した場合のコード生成精度(Pass@1)にどう影響するか?
- RQ2信頼性やコードスメルなど、コード品質属性に影響を与える開発活動はどれか?
- RQ3異なる GPT-3.5 モデルバージョンと温度設定で LCG の結果はどれくらい安定しているか?
主な発見
| モデル | HumanEval | HumanEval-ET | MBPP | MBPP-ET |
|---|---|---|---|---|
| GPT | 64.4 ± 3.7 | 49.8 ± 3.0 | 77.5 ± 0.8 | 53.9 ± 0.7 |
| LCG_Waterfall | 69.5 ± 2.3 | 59.4 ± 2.5 | 76.3 ± 0.9 | 51.1 ± 1.7 |
| LCG_TDD | 69.8 ± 2.2 | 60.0 ± 2.1 | 76.8 ± 0.9 | 52.8 ± 0.7 |
| LCG_Scrum | 75.2 ± 1.1 | 65.5 ± 1.9 | 82.5 ± 0.6 | 56.7 ± 1.4 |
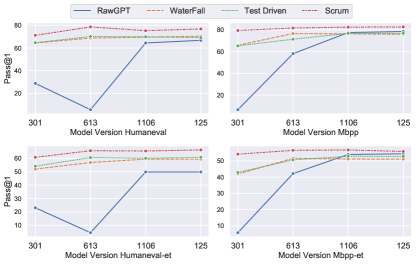
- LCG_Scrum はすべてのベンチマークで最高の Pass@1 を達成: 75.2 (HumanEval)、65.5 (HumanEval-ET)、82.5 (MBPP)、56.7 (MBPP-ET)。
- LCG のバリアントは一般的に GPT ベースラインを上回り、Pass@1 の向上は 5.2% 〜 31.5%である。
- LCG_Scrum はベンチマーク全体で平均標準偏差が 1.3% と最も安定した結果を示す。
- テストを除去すると Pass@1 は大幅に低下(17.0%低下、56.1%)し、コードスメルが増える。
- 設計およびコードレビューはリファクタリング・警告スメルを減少させ、例外処理を改善する。
- GPT モデルバージョンの差は品質に大きく影響する一方、LCG はバージョンと温度設定を横断して安定性を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。