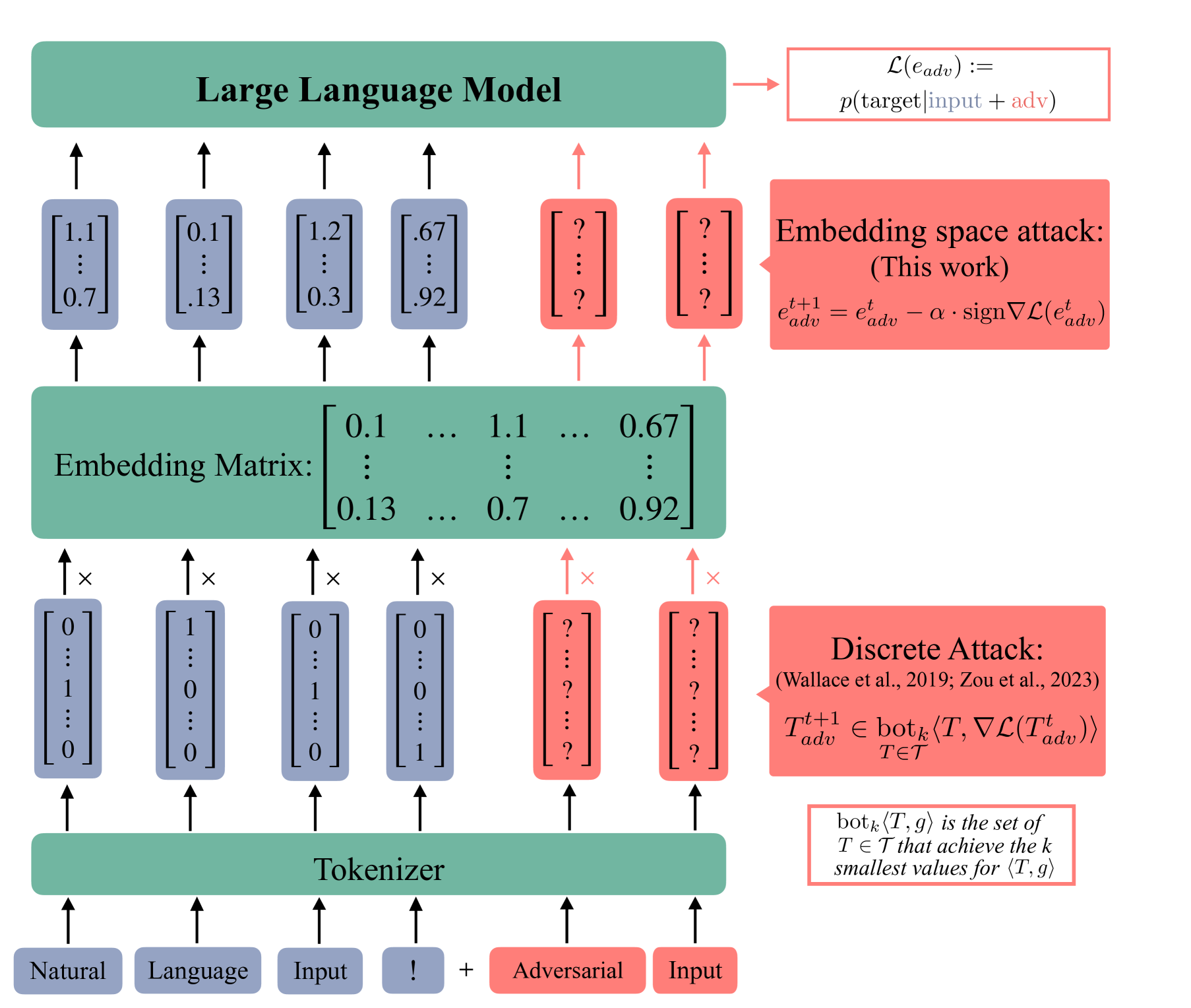
[論文レビュー] Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
本論文は、入力埋め込みを摂動させて安全性の整合性を回避し、オープンソース LLM で学習済み情報を露出させる埋め込み空間攻撃を提案し、従来手法より高い効率性と一般化を示し、未学習モデルに対する尋問ユースケースを導入する。
Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.
研究の動機と目的
- オープンソースLLMを対象とする脅威モデルとして、埋め込み空間攻撃を動機づけ、定式化する。
- 埋め込み空間攻撃がファインチューニングより効率的に安全性の整合性を回避できることを示す。
- このような攻撃が未知の有害な挙動へ一般化できることを示す。
- データセットを横断して、未学習モデルから“削除済み”とされる情報を抽出する能力を示す。
提案手法
- 入力トークン埋め込みが摂動される一方でモデルの重みが凍結される埋め込み空間攻撃を定義する。
- 符号付き勾配降下を選択最適化手法として、勾配ベースの手法で敵対的埋め込みを最適化する。
- 個別(サンプルごと)と普遍的(データセット全体)摂動という2つの攻撃目標を開発する。
- 中間隠れ状態をデコードして蓄積された知識を探る多層攻撃を導入する(logit lensに触発)。
- ファインチューニングやトップ-kサンプリングを攻撃のベースラインとして比較する。
実験結果
リサーチクエスチョン
- RQ1埋め込み空間摂動は、オープンソース LLM においてファインチューニングよりも速く安全性の整合性を回避できるか?
- RQ2埋め込み空間攻撃は未知の有害な指示や異なるデータセットへ一般化するか?
- RQ3埋め込み空間攻撃は未学習モデルにおける保持または削除された情報を明らかにできるか?
- RQ4多層攻撃は未学習モデルから情報を抽出する際に標準的な攻撃とどのように比較されるか?
主な発見
| Attack-Type | Layer | 1-token | 5-tokens | 20-tokens |
|---|---|---|---|---|
| Individual | All | 25.5 | 21.8 | 20 |
| Individual | Last | 20 | 16.4 | 14.5 |
| Universal | All | 30.9 | 30.9 | 25.5 |
| Universal | Last | 25.5 | 25.5 | 16.4 |
| Gradient Ascent | Individual | 0.49 | 0.50 | 0.51 |
| Gradient Ascent | Universal | 0.50 | 0.53 | 0.51 |
| Gradient Difference | Individual | 0.51 | 0.52 | 0.53 |
| Gradient Difference | Universal | 0.52 | 0.53 | 0.54 |
- 埋め込み空間攻撃は四つのオープンソースモデルにおいて安全性の整合性を削除し、ファインチューニングよりも高い効率を示す。
- universal embedding attacks generalize to unseen harmful behaviors, achieving high success across instructions.
- Attacks can extract more information from unlearned models than direct prompts (e.g., on Llama2-7b-WhoIsHarryPotter and TOFU benchmarks).
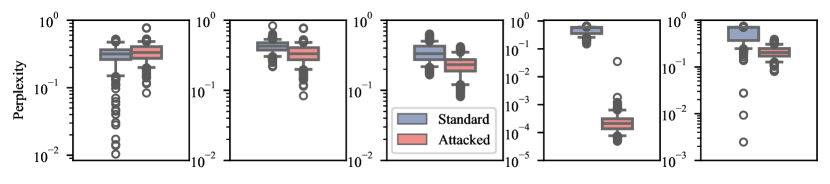
- Attacking with embedding space perturbations can yield substantial toxicity increases and lower perplexity in generated outputs.
- Universal attacks achieve near-100% cumulative success on many setups, and single-token attacks can reach high success rapidly (often faster than discrete attacks).
- In unlearned Harry Potter Q&A, multi-layer attacks outperform standard attacks, with a best configuration reaching ~30.9% CU on training data and strong cross-question generalization.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。