[論文レビュー] SOLAR: Deep Structured Representations for Model-Based Reinforcement Learning
SOLAR は潜在表現とグローバル潜在線形二次系(LQS)ダイナミクスを学習し、画像からのデータ効率の高いモデルベースRLを可能にする。ローカル TVLG モデルと LQR-FLM を用いて方策改善; Sawyer ロボット実機タスクで高い画像ベースの自律性を実証。
Model-based reinforcement learning (RL) has proven to be a data efficient approach for learning control tasks but is difficult to utilize in domains with complex observations such as images. In this paper, we present a method for learning representations that are suitable for iterative model-based policy improvement, even when the underlying dynamical system has complex dynamics and image observations, in that these representations are optimized for inferring simple dynamics and cost models given data from the current policy. This enables a model-based RL method based on the linear-quadratic regulator (LQR) to be used for systems with image observations. We evaluate our approach on a range of robotics tasks, including manipulation with a real-world robotic arm directly from images. We find that our method produces substantially better final performance than other model-based RL methods while being significantly more efficient than model-free RL.
研究の動機と目的
- 高次元の画像観測を伴う領域でデータ効率の良い RL を動機づける。
- 正確な局所線形ダイナミクスと二次コストモデリングを可能にする表現を開発する。
- グローバルな潜在LQSモデリングと局所後方推論を組み合わせて方策改善を行う。
- 画像ベースのロボットタスクにおける転移とスパース報酬能力を実証する。
提案手法
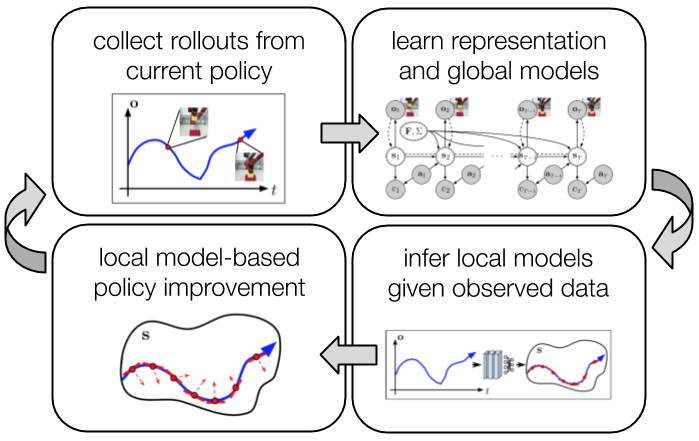
- 潜在表現を用いた確率的最適制御 SOLAR フレームワークを提案し、潜在空間とグローバル線形ガウスダイナミクス priors を共同学習する。
- 画像を潜在状態に写像し観測を再構成するために畳み込みエンコーダ/デコーダを用いる。
- ダイナミクス(F, Sigma)に対するグローバルプリオリを MNIW を用いて採用し、軌道間のダイナミクスのばらつきを捉える。
- データに条件付けた後方推定により各時点で局所の時変線形ダイナミクスを推定し、グローバルプリオリからの経験ベイズ更新として扱う。
- p(o_t|s_t) および p(c_t|s_t,a_t) の項を含む変分オートエンコーダ風目的関数(ELBO)を適用し、q(F,Sigma) にKLペナルティを課す。
- LQR-FLM(KL制約付きLQR)で方策を更新し、データに近い軌道分布を維持してモデリングバイアスを緩和する。

実験結果
リサーチクエスチョン
- RQ1SOLAR はフォワードモデル予測なしで高次元画像観測から直接有効な方策を学習できるか?
- RQ2局所線形二次モデリングの最適化に用いられる潜在表現は、標準のモデルベース/モデルフリーのベースラインと比較してデータ効率と最終性能を改善するか?
- RQ3SOLAR は共有ダイナミクスファミリ内の新しいタスクへ学習済み表現/モデルを転移でき、スパース報酬信号を扱えるか?
- RQ4実世界の画像ベースロボット操作タスクでの性能はどうか?
主な発見
- SOLAR は画像ベースの制御タスクで他のモデルベースRL手法より著しく良い最終性能を達成する。
- SOLAR は評価された領域でモデルフリーRLよりデータ効率が著しく高い。
- 64×64×3 の画像観測を用いた実世界のロボティック操作で成功、Sawyerアームによるブロック積みと押し動作を含む。
- 複数タスクから学習したベースモデルは同一分布内の新しいタスクへ転移でき、学習を加速する。
- グラフィカルモデルを拡張し、人間提供のバイナリ成功信号を用いることでスパース報酬設定をサポート。
- 学習済みモデルを用いたMPCおよびVAEベースラインと比較して、SOLARは長期的な性能とデータ効率で複数の画像ベースタスクで優る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。