[論文レビュー] Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Sophiaは対角ヘシアン事前条件付けと各座標クリッピングを用いた軽量な2次最適化手法を導入し、GPTのような言語モデルの事前学習においてAdamWと比べて約2倍の速度向上を達成するが、大きなオーバーヘッドはない。
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT models of sizes ranging from 125M to 1.5B, Sophia achieves a 2x speed-up compared to Adam in the number of steps, total compute, and wall-clock time, achieving the same perplexity with 50% fewer steps, less total compute, and reduced wall-clock time. Theoretically, we show that Sophia, in a much simplified setting, adapts to the heterogeneous curvatures in different parameter dimensions, and thus has a run-time bound that does not depend on the condition number of the loss.
研究の動機と目的
- 言語モデルの事前学習の高コストと、Adam以外のより高速な最適化手法の必要性を動機づけ、対応する。
- 曲率情報を活用しつつ、 per-step オーバーヘッドを削減する軽量な2次最適化手法を開発する。
- モデル性能を損なうことなく、訓練ステップ数、総計算量、実時間を大幅に削減する。
- 対角ヘシアン事前条件付けがパラメータ間の異質な曲率に適応することを理論・実証的に示す。
提案手法
- Sophiaを提案する。これは、勾配の移動平均を対角ヘシアン推定値の移動平均で割って更新方向とする。
- 対角ヘシアンをkステップごとに推定する(k=10)。2つのオプション: Hutchinson の無偏推定(ヘシアン−ベクトル積)と Gauss-Newton-Bartlett(GNB)推定(Gauss-Newton/ヘシアンの対角要素)を使用。
- 最悪ケースの更新サイズを制御し、非凸の風景での頑健性を確保するために、座標ごとのクリッピングを適用。
- 更新則は勾配EMA、対角ヘシアン事前条件付け、およびクリッピングを組み合わせる: theta_{t+1} = theta_t - η_t * clip(m_t / max{γ * h_t, ε}, 1)。
- PSD(正定値対称)事前条件付けのために対角ヘシアンの正値エントリを保持し、下降方向を保証。
- 既存のパイプラインへの実用的な統合を、最小のオーバーヘッドで実現し、PyTorch/JAXと互換性があることを示す。
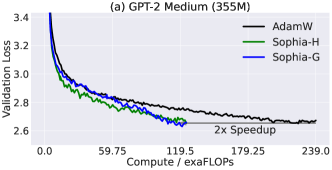
実験結果
リサーチクエスチョン
- RQ1対角ヘシアンベースの軽量な事前条件付けとクリッピングは、AdamWと比較して言語モデルの事前学習を加速できるか。
- RQ22つの推定法(Hutchinson と Gauss-Newton-Bartlett)は、巨大言語モデルにおいてオーバーヘッドを許容しつつ信頼性の高い対角ヘシアン推定を提供するか。
- RQ3Sophiaは125Mから6.6Bパラメータのモデル規模で、同じ検証損失に到達するまでのステップ数と総計算量の観点でどのように性能を示すか。
- RQ4座標ごとのクリッピング機構は、非凸LLMの風景における安定性と収束を改善するか。
- RQ5Sophiaの異質な曲率への適応と、簡略化された設定における条件数に対する実行時間の独立性を説明する理論的洞察は何か。
主な発見
- SophiaはGPT-2およびGPT NeoXの事前学習において、モデルサイズに関係なく、ステップ数・総計算量・実時間の約2倍の速度向上を達成する。
- Sophiaは検証用の事前学習損失と同じ値を、約50%少ないステップ、約50%少ない総計算量と実時間で達成する。
- 125Mから1.5B+パラメータのモデルサイズにまたがって、SophiaとAdamWの間の性能ギャップは大きなモデルほど拡大する。
- 2つの対角ヘシアン推定(HutchinsonとGauss-Newton-Bartlett)は、1ステップあたり約5%のオーバーヘッドを導入し、スケーラブルな前条件付けを可能にする。
- クリッピング機構は負の曲率と急激なヘシアン変化を防ぎ、頑健な訓練を実現し、ニュートン様の失敗を防ぐ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。