[論文レビュー] Sources of Hallucination by Large Language Models on Inference Tasks
本論文は、自然言語推論(NLI)の過程でLLMの幻覚を引き起こす、事前学習によって生じる2つの偏りを特定する:検証済み仮説の memorization(記憶化)とコーパス頻度に基づく含意。これらの偏りは偽陽性を引き起こし、LLaMA、GPT-3.5、PaLM 全体の非整合サンプルで性能を低下させることを示す。
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two biases originating from pretraining which predict much of their behavior, and show that these are major sources of hallucination in generative LLMs. First, memorization at the level of sentences: we show that, regardless of the premise, models falsely label NLI test samples as entailing when the hypothesis is attested in training data, and that entities are used as ``indices'' to access the memorized data. Second, statistical patterns of usage learned at the level of corpora: we further show a similar effect when the premise predicate is less frequent than that of the hypothesis in the training data, a bias following from previous studies. We demonstrate that LLMs perform significantly worse on NLI test samples which do not conform to these biases than those which do, and we offer these as valuable controls for future LLM evaluation.
研究の動機と目的
- LLMの自然言語推論における幻覚を導くバイアスを識別する。
- memorization-based と corpus-statistic バイアスを事前学習アーティファクトとして区別する。
- これらのバイアスが検証済み仮説と頻度ベースの含意に対する予測にどのように影響するかを評価する。
提案手法
- 制御済みデータセット変換を用いたLLaMA-65B、GPT-3.5、PaLM-540Bでの行動的NLI実験を実施。
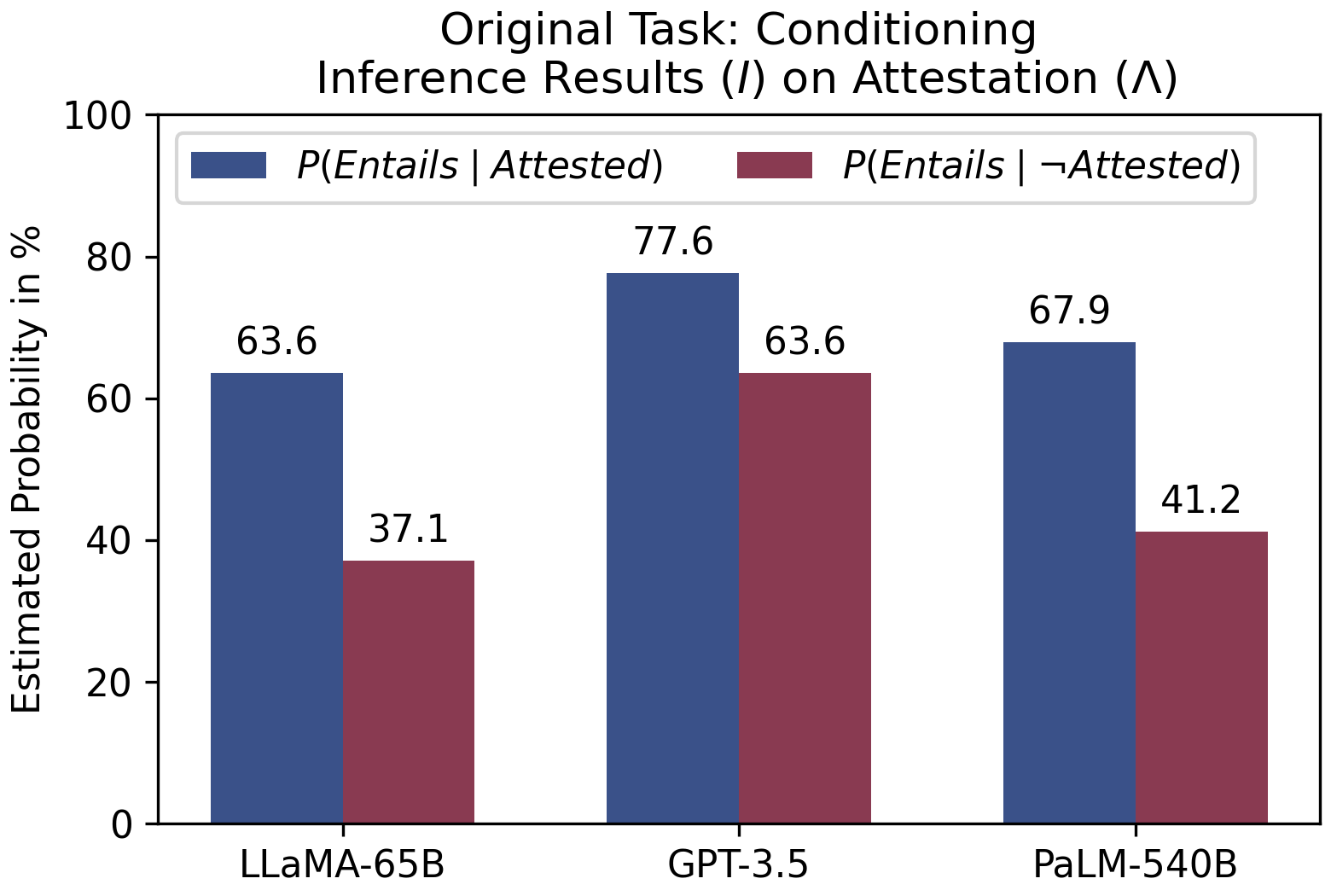
- Attestation Bias (Λ) をトレーニングデータの仮説検証依存として定義し、attestation promptsで測定。
- Relative Frequency Bias (Φ) をトレーニングコーパスの前提と仮説の頻度に基づき、Google N-gramsを代理指標として定義。
- Levy/Holt and RTE-1 style prompts を三者択一のNLI選択肢と最小限のfew-shotサンプルで用い、記憶とバイアス効果を検出。
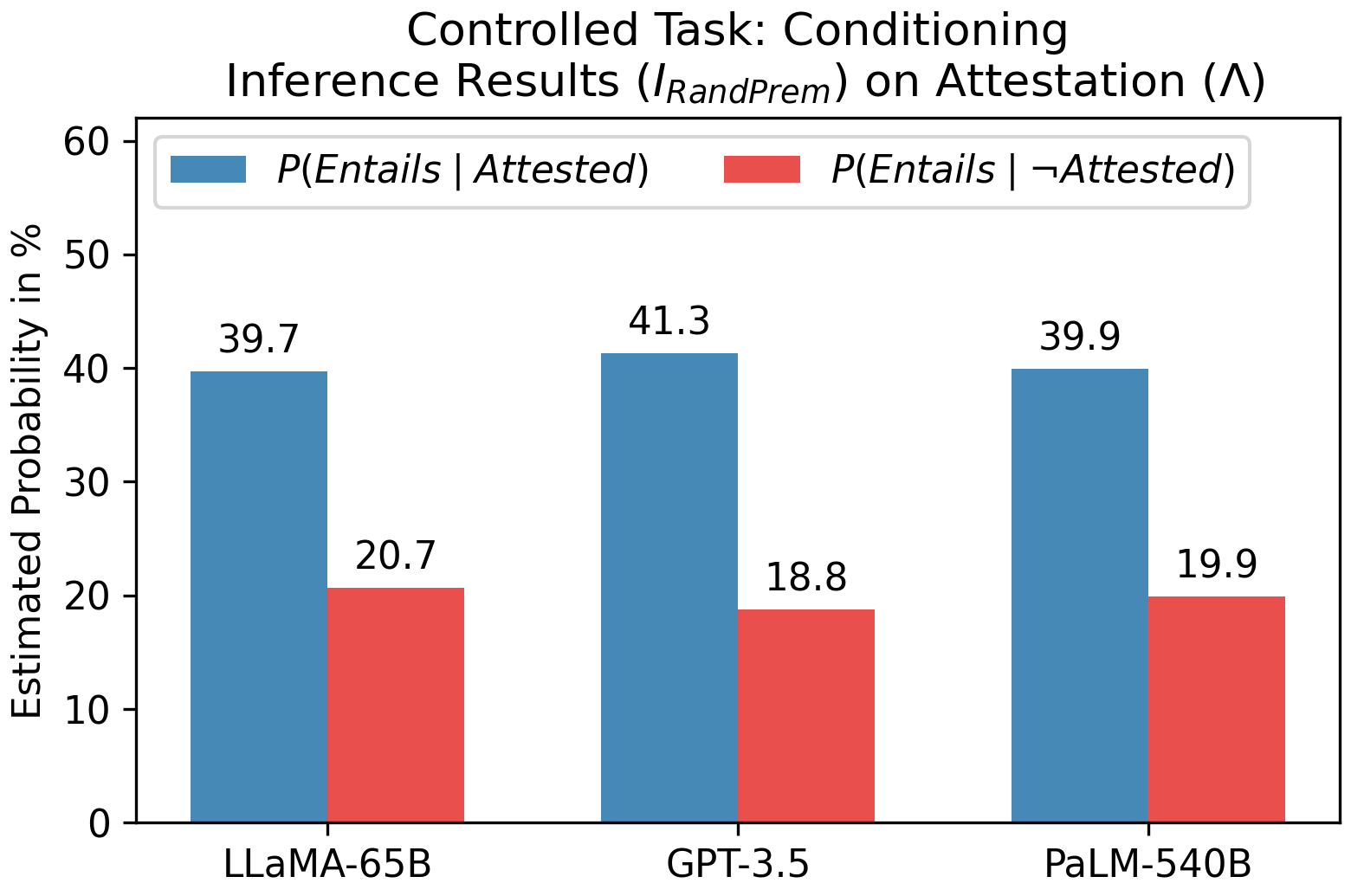
- I_RandPrem、I_GenArg、I_RandArg、I_RandArg↑/↓ などのデータセット変換を適用し、記憶効果を表層信号から分離。
- 記憶・頻度に基づくバイアスの影響を recall/precision 指標および bias-consistent vs adversarial サブセットの AUC_norm で評価。
実験結果
リサーチクエスチョン
- RQ1LLMsはNLIタスクを解く際にトレーニングデータの命題的な記憶を頼りにしているのか?
- RQ2名前付きエンティティは推論における記憶参照のための指標として重要か?
- RQ3コーパス頻度バイアスは意味内容とは独立して含意判断を導くのか?
- RQ4これらのバイアスはバイアスに適合するサンプルと矛盾するサンプルの性能にどのように影響するのか?
主な発見
- LLMs は仮説がトレーニングデータで検証済みである場合に含意予測を高く示すことが多く、Attestation Bias (Λ) を示す。
- エンティティを一般的またはランダムなものに置換するとリコールが低下し、名前付きエンティティがリコールの記憶参照として機能していることを示唆。
- モデルは Relative Frequency Bias (Φ) を示し、前提が仮説よりも訓練データで頻度が低い場合に含意が生じやすい。
- LLaMA、GPT-3.5、PaLM を跨いで、記憶・頻度に基づくバイアスが多くの偽陽性を引き起こし、敵対的サンプルでの性能を低下させる。
- Attestation および Frequency バイアスはモデルファミリーを超えて持続し、微調整や RLHF ではなく事前学習目的に結びついている。
- bias-consistent vs bias-adversarial サブセットで評価した場合、従来のNLIスコアは真の推論能力を誤解させる可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。