[論文レビュー] Sparks of GPTs in Edge Intelligence for Metaverse: Caching and Inference for Mobile AIGC Services
本論文は、モバイルエッジサーバー上の事前学習済み基盤モデルの共同モデルキャッシュと推論フレームワークを提案し、Age of Context(AoC)を導入し、Least Context(LC)アルゴリズムがシステムコストを削減しエッジ実行を改善することを示す。
Aiming at achieving artificial general intelligence (AGI) for Metaverse, pretrained foundation models (PFMs), e.g., generative pretrained transformers (GPTs), can effectively provide various AI services, such as autonomous driving, digital twins, and AI-generated content (AIGC) for extended reality. With the advantages of low latency and privacy-preserving, serving PFMs of mobile AI services in edge intelligence is a viable solution for caching and executing PFMs on edge servers with limited computing resources and GPU memory. However, PFMs typically consist of billions of parameters that are computation and memory-intensive for edge servers during loading and execution. In this article, we investigate edge PFM serving problems for mobile AIGC services of Metaverse. First, we introduce the fundamentals of PFMs and discuss their characteristic fine-tuning and inference methods in edge intelligence. Then, we propose a novel framework of joint model caching and inference for managing models and allocating resources to satisfy users' requests efficiently. Furthermore, considering the in-context learning ability of PFMs, we propose a new metric to evaluate the freshness and relevance between examples in demonstrations and executing tasks, namely the Age of Context (AoC). Finally, we propose a least context algorithm for managing cached models at edge servers by balancing the tradeoff among latency, energy consumption, and accuracy.
研究の動機と目的
- エッジでGPTなどのPFMを用いてAGI対応のメタバースサービスを動機づけ、低遅延でプライバシー保護されたAIGCを実現する。
- モバイルエッジとクラウド層全体でリソース配分を最適化する共同のモデルキャッシュと推論フレームワークを開発する。
- AoCを導入し、インコンテキストデモの関連性と新鮮さを測定する。
- 文脈的有用性に基づいてキャッシュされたPFMを管理するLeast Context(LC)キャッシュアルゴリズムを提案する。
提案手法
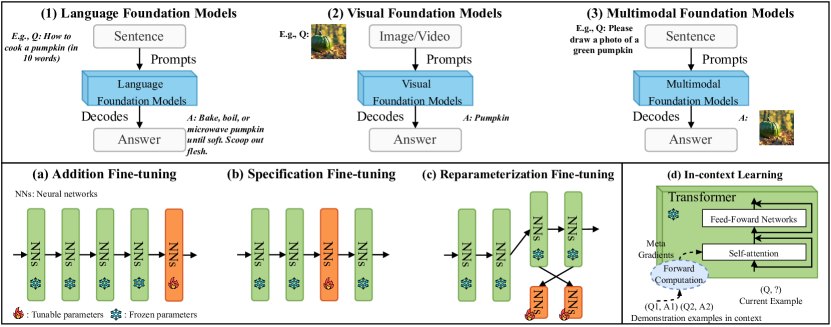
- PFMをLFMs、VFMs、MFMsに分類し、エッジ環境での微調整と推論アプローチを要約する。
- エッジ-クラウド協調と動的キャッシュ管理を備えた共同のモデルキャッシュと推論フレームワークを定義する。
- インコンテキスト学習中の文脈例の新鮮さ/関連性を捉える指標としてAoCを導入する。
- GPUメモリが必要な場合、最も少ない文脈例を持つキャッシュ済みモデルを追い出すLCアルゴリズムを提案する。
- 複数指標コストモデルにわたって、Random、Cloud、FIFO、LFUのベースラインと比較評価を提供する。
- 例示的なユースケースを提示し、結果表(Table II)を通じて性能を分析する。
実験結果
リサーチクエスチョン
- RQ1モバイルエッジクラウドシステムは、遅延と精度の目標を満たすようにPFMsを最適にキャッシュして実行するにはどうすべきか?
- RQ2エッジ環境におけるインコンテキスト学習の文脈(AoC)がPFM推論性能に与える影響はどの程度か?
- RQ3Least Contextキャッシュ戦略は、システムコストとエッジ実行率の観点で従来のキャッシュ方針を上回るか?
主な発見
| 指標 | Random | クラウド | FIFO | LFU | LC |
|---|---|---|---|---|---|
| システムコスト | 25.67 | 7.29 | 27.51 | 5.93 | 4.88 |
| スイッチングコスト | 18.72 | 0 | 23.28 | 0.37 | 0.32 |
| 総精度コスト | 0.13 | 0 | 0.52 | 0.36 | 0.44 |
| 平均精度コスト | 0.0151 | 0 | 0.0085 | 0.0083 | 0.0076 |
| 推論待機遅延 | 0.12 | 0 | 1.30 | 1.32 | 1.26 |
| オフロード待機遅延 | 0.04 | 0 | 0.35 | 0.24 | 0.31 |
| クラウドコスト | 6.63 | 7.29 | 2.05 | 3.63 | 2.52 |
| エッジ実行比率 | 9.8% | 0% | 70.7% | 49.4% | 65.0% |
- LCアルゴリズムはベースラインと比較して総合システムコストを削減する。
- LCは一部のベースラインよりエッジ実行比率を高く、エッジでの推論を増やすことを示す。
- AoCベースの文脈管理により、インコンテキスト学習をより効果的に活用して精度を向上させる。
- 実験では、LCが平均精度コストを低く抑え、代替案に対して推論/遅延指標も競争力がある。
- このフレームワークは、動的で文脈認識的なキャッシュを備えたエッジ-クラウド共同作業がモバイルAIGCサービスに有益であることを示している。
![Figure 2: An illustration of the performance of zero-, one-, and few-shot accuracy under different model caching settings [ 3 ] .](https://ar5iv.labs.arxiv.org/html/2304.08782/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。