[論文レビュー] Sparse Autoencoders Find Highly Interpretable Features in Language Models
本論文は疎なオートエンコーダを用いて言語モデルの活性化から特徴の辞書を学習し、解釈性が高くモノ意味的な方向を生み出し、モデル出力に因果的な影響を与え、重ね合わせを低減できる。
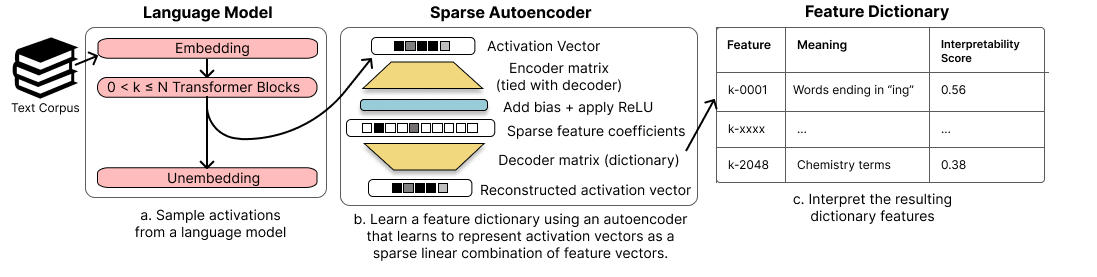
One of the roadblocks to a better understanding of neural networks' internals is extit{polysemanticity}, where neurons appear to activate in multiple, semantically distinct contexts. Polysemanticity prevents us from identifying concise, human-understandable explanations for what neural networks are doing internally. One hypothesised cause of polysemanticity is extit{superposition}, where neural networks represent more features than they have neurons by assigning features to an overcomplete set of directions in activation space, rather than to individual neurons. Here, we attempt to identify those directions, using sparse autoencoders to reconstruct the internal activations of a language model. These autoencoders learn sets of sparsely activating features that are more interpretable and monosemantic than directions identified by alternative approaches, where interpretability is measured by automated methods. Moreover, we show that with our learned set of features, we can pinpoint the features that are causally responsible for counterfactual behaviour on the indirect object identification task \citep{wang2022interpretability} to a finer degree than previous decompositions. This work indicates that it is possible to resolve superposition in language models using a scalable, unsupervised method. Our method may serve as a foundation for future mechanistic interpretability work, which we hope will enable greater model transparency and steerability.
研究の動機と目的
- 言語モデルにおける多義性と重ね合わせに対処することで機構的解釈可能性を動機づける。
- 内部活性化から解釈可能な特徴方向を抽出する教師なし手法を開発する。
- 学習された辞書特徴がベースラインよりも高い自動解釈性を達成することを示す。
- 特定タスクにおけるモデル挙動に対する辞書特徴の因果的関連性を示す。
提案手法
- 隠れ層活性化に対してスパース性ペナルティを課した疎なオートエンコーダを訓練し、言語モデルの活性化(残差ストリーム、MLPサブレイヤ、またはアテンションヘッドのサブレイヤ)から特徴の辞書を学習する。
- エンコーダー/デコーダーの重みを結びつけ、辞書特徴を行ごとに正規化する。
- 再構成損失をL1スパース性項で最適化して真の特徴を回復する(L2再構成損失 + alpha * ||c||1)。
- 辞書特徴活性化の言語モデルによる説明から導出された自動解釈性スコアで解釈可能性を評価する。
- 学習された特徴の解釈可能性について、デフォルト基底、ランダム方向、PCA、ICAなどのベースラインと比較する。
- 辞書特徴の因果的影響を Indirect Object Identification (IOI) タスクに局在化するため、活性化パッチ適用と Automated Circuit Discovery (ACDC) を適用する。
実験結果
リサーチクエスチョン
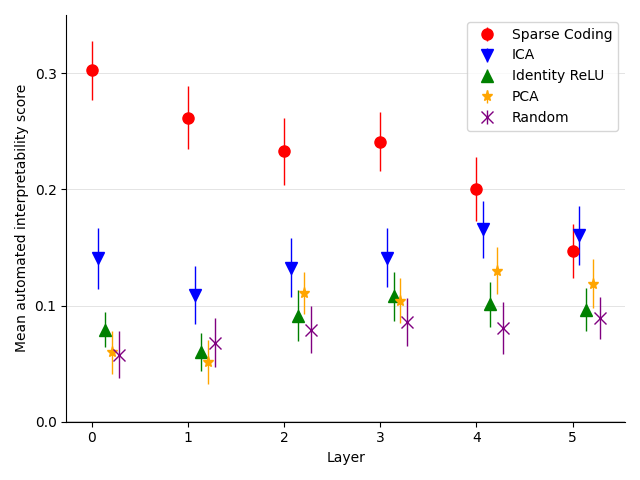
- RQ1疎な辞書特徴は他の分解法と比較して多義性を低減し、解釈性を高めるか?
- RQ2疎な辞書特徴を用いて特定のタスクでモデル出力を正確に局在化し、因果的な影響を与えることができるか?
- RQ3解釈可能性と出力への因果効果の観点で、辞書特徴はPCA/ICA/ランダムベースラインと比べてどう機能するか?
- RQ4学習特徴の質と有用性における疎性レベルと辞書サイズの役割は何か?
主な発見
- 辞書特徴は、ニューロンやいくつかのベースラインよりも平均的に解釈可能であると自動解釈性スコアで測定される。
- Sparse dictionaries localize causal features for IOI more efficiently (fewer patches) and with smaller edits than PCA-based decompositions.
- モノ意味的な辞書特徴が現れ、狭い語彙トークン(例:アポストロフィー、ピリオド)で活性化し、次のトークンのロジットに予測可能な影響を持つ。
- Activation patching with sparse dictionaries achieves a better Pareto frontier of edit magnitude versus thoroughness of editing compared to non-sparse dictionaries.
- Case studies show features that correspond to interpretable linguistic phenomena and reveal upstream/downstream causal relationships across layers.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。