[論文レビュー] Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
Sparse4D v2 は、Sparse4D v2 introduces a recurrent temporal fusion module for sparse multi-view 3D detection, reducing temporal fusion from O(T) to O(1) and achieving state-of-the-art results on nuScenes, with Efficient Deformable Aggregation and camera-parameter encoding improving efficiency and robustness.
Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.
研究の動機と目的
- Motivate improved sparse-based perception for autonomous driving by enabling efficient long-term temporal fusion.
- Develop a recurrent temporal fusion mechanism that decouples image features from instance states to reduce computation.
- Enhance training and robustness through camera-parameter encoding and dense depth supervision.
- Improve memory efficiency and inference speed via an optimized deformable aggregation operation.
- Demonstrate state-of-the-art performance on nuScenes compared to BEV-based and other sparse methods.
提案手法
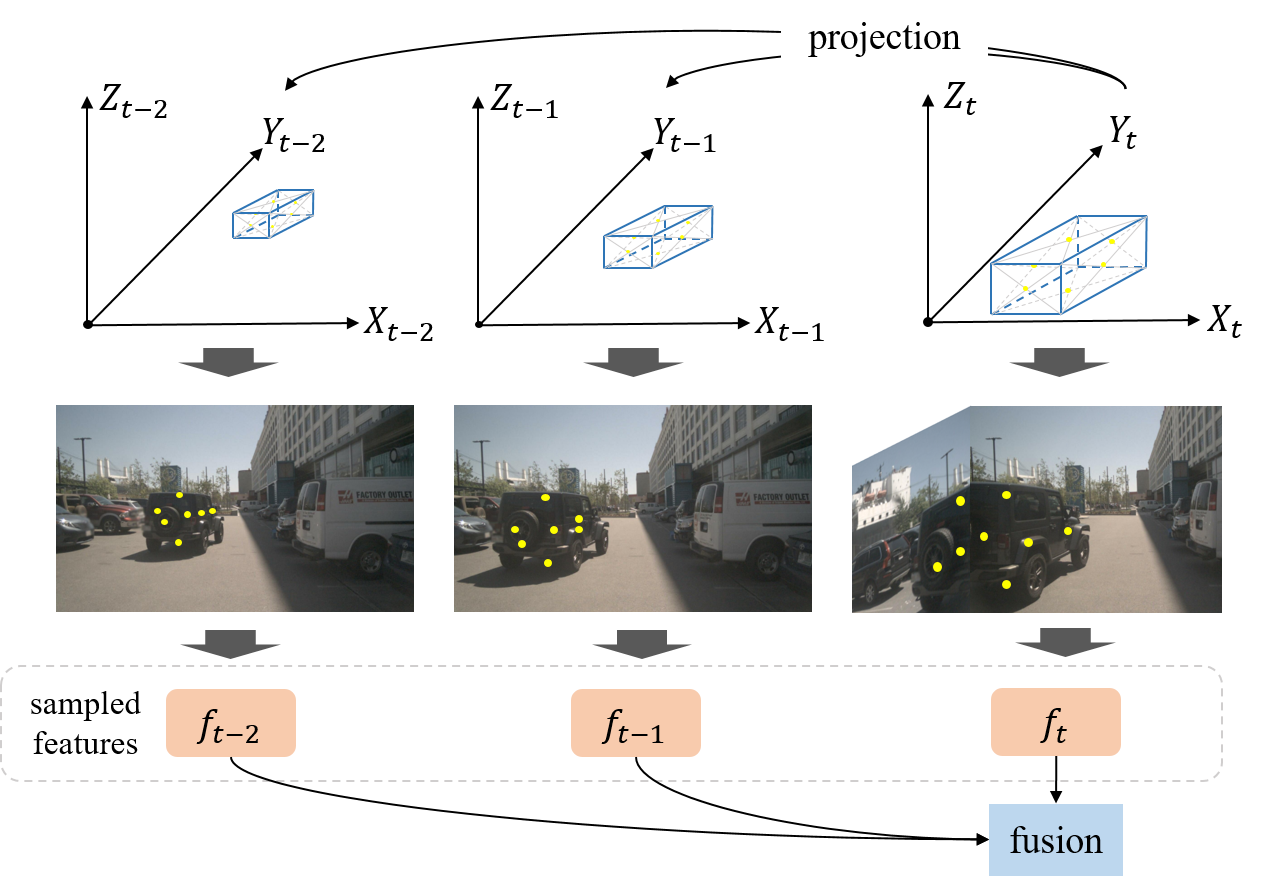
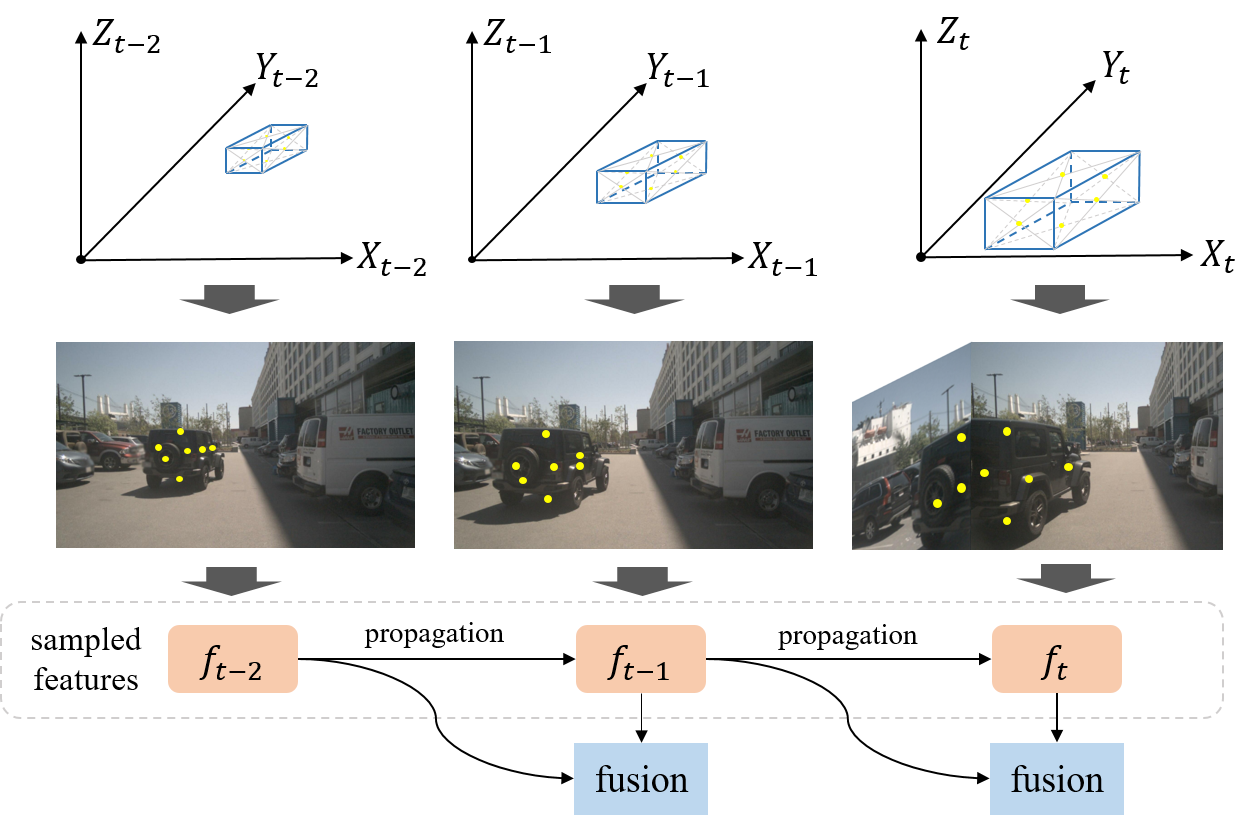
- Replace multi-frame sampling with a recurrent temporal propagation of instance features across frames.
- Decouple image features and instance states using anchor, instance feature, and anchor embedding, with a lightweight anchor encoder Psi for temporal projection.
- Propagate anchors through ego-motion to current frame and re-encode their position embeddings for temporal cross-attention in the decoder.
- Introduce Efficient Deformable Aggregation (EDA) to fuse multi-view, multi-scale features as a single CUDA operation, reducing memory and increasing speed.
- Incorporate camera parameter encoding directly into the view-weight computation to improve robustness to camera variations.
- Add dense depth supervision from LiDAR point clouds to stabilize and accelerate training, with a later removal of the depth-reweight module.
実験結果
リサーチクエスチョン
- RQ1How can temporal fusion for sparse multi-view 3D detection be made independent of the number of historical frames to improve speed and memory usage?
- RQ2Can instance-level temporal propagation with ego-motion-based anchoring replace multi-frame sampling without sacrificing accuracy?
- RQ3Does explicitly encoding camera parameters and incorporating dense depth supervision improve robustness and detection performance across viewpoints and scenarios?
- RQ4What are the efficiency and memory benefits of a redesigned deformable aggregation operator in sparse temporal fusion?
主な発見
- Sparse4Dv2 achieves faster inference and lower memory usage than Sparse4Dv1, with substantial gains across frames (example: FPS and GPU memory improvements on RTX 3090).
- The recurrent temporal fusion enables long-term information fusion without increasing the number of anchors, maintaining comparable inference speed to non-temporal models.
- Efficient Deformable Aggregation (EDA) reduces training memory by about half and increases training batch size and overall speed, while also boosting inference FPS by about 42%.
- Camera parameter encoding improves orientation and overall perception metrics; removing it degrades mAP and mAOE.
- Dense depth supervision significantly boosts performance (e.g., reductions in gradient collapse and improved mAP/NDS when enabled).
- On nuScenes validation with ResNet50 and 256x704 input, Sparse4Dv2 achieves mAP 0.439 and NDS 0.539, outperforming several BEV-based and sparse baselines; on test, Sparse4Dv2 with VovNet-99 reaches mAP 0.557 and NDS 0.638, indicating SOTA potential.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。