[論文レビュー] Spatial Transform Decoupling for Oriented Object Detection
STDはViTベースの検出器に対して多分岐のデカップリングされたパラメータ予測ヘッドを導入し、階層的な活性化マスクと組み合わせて回転方向検出の特徴を段階的に洗練させ、DOTA-v1.0およびHRSC2016で最先端の結果を達成します。
Vision Transformers (ViTs) have achieved remarkable success in computer vision tasks. However, their potential in rotation-sensitive scenarios has not been fully explored, and this limitation may be inherently attributed to the lack of spatial invariance in the data-forwarding process. In this study, we present a novel approach, termed Spatial Transform Decoupling (STD), providing a simple-yet-effective solution for oriented object detection with ViTs. Built upon stacked ViT blocks, STD utilizes separate network branches to predict the position, size, and angle of bounding boxes, effectively harnessing the spatial transform potential of ViTs in a divide-and-conquer fashion. Moreover, by aggregating cascaded activation masks (CAMs) computed upon the regressed parameters, STD gradually enhances features within regions of interest (RoIs), which complements the self-attention mechanism. Without bells and whistles, STD achieves state-of-the-art performance on the benchmark datasets including DOTA-v1.0 (82.24% mAP) and HRSC2016 (98.55% mAP), which demonstrates the effectiveness of the proposed method. Source code is available at https://github.com/yuhongtian17/Spatial-Transform-Decoupling.
研究の動機と目的
- リモートセンシングにおける回転感度のある検出をViTで解決する。
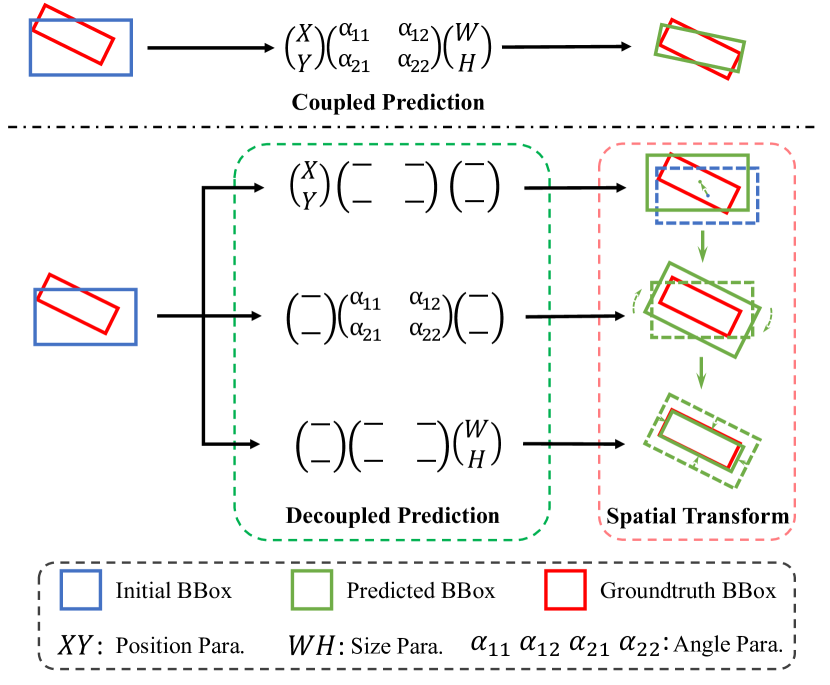
- 位置、サイズ、角度を別々に推定するデカップリングされた多分岐予測ヘッドを提案する。
- RoIsの自己アテンションを導く階層的活性化マスクによる特徴 refinementを強化する。
- STDのViTベース検出器とベンチマーク全体への一般化可能性を示す。
提案手法
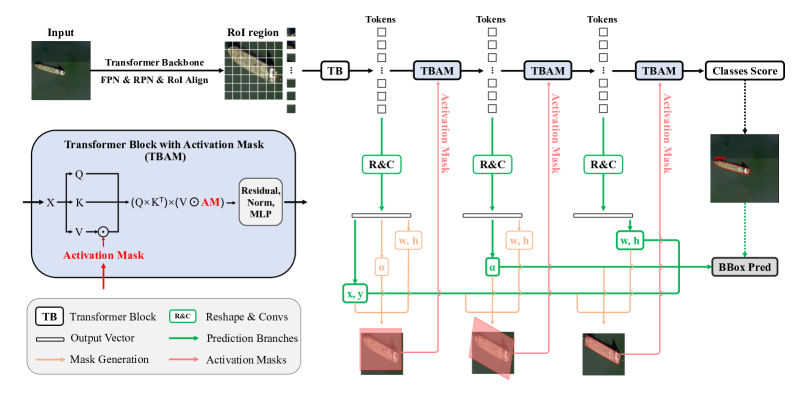
- 各ブランチが異なる空間変換パラメータ(x,y)、角度α、(w,h)およびクラススコアを、徐々に深くなるTransformerブロックから予測する多分岐ネットワークを使用する。
- 特徴抽出をデカップル化し、異なるTransformerブロックからの異なる特徴マップを各パラメータに割り当てる。CAMs(階層的活性化マスク)を導入してピクセルレベルの監督を提供し、foreground領域へ自己アテンションを誘導する。
- CAMsは予測ボックスパラメータに従って単位活性化マスクをアフィン変換して算出し、TBAM(活性化マスク付きTransformerブロック)内で適用してVを変調する。
- MAEで事前学習したViTベースのバックボーンを用いたFaster R-CNNフレームワーク内で訓練し、Oriented RCNNとの互換性も示す。
- 任意でMAEBBoxHeadを事前学習させ、STDを適用して4つのTransformerレイヤーにわたる段階的 refinementを達成する。
実験結果
リサーチクエスチョン
- RQ1デカップリングされたパラメータ特異的な特徴マップはViTベース検出器における姿勢回帰を統合ヘッドより改善するか。
- RQ2階層的な活性化マスクは密な段階別のガイダンスを提供し、RoI特徴の refinementと回転検出の全体的なmAPを改善するか。
- RQ3STDは異なるViTバックボーンやRoI抽出法に対して一般化可能で、精度を維持または向上させるか。
- RQ4パラメータ予測順序とCAM統合がSTDの性能に与える影響はどうか。
- RQ5STDはDOTA-v1.0およびHRSC2016などの標準的な向き物体ベンチマークで、最先端手法と比較してどうか。
主な発見
- STDはDOTA-v1.0およびHRSC2016ベンチマークで最先端の性能を達成(例:STD-OでDOTA-v1.0のmAP 82.24%、HRSC2016のmAP 98.55)。
- 境界ボックスパラメータ(x,y) -> α -> (w,h)の階層的・レイヤーごとのデカップリングは、単一特徴ヘッドのベースラインより姿勢精度を改善する。
- CAMは予測パラメータの意味に対応するアテンションマップを密に導くガイダンスを提供し、foregroundの焦点を高め背景の混同を減少させる。
- STDは複数のバックボーン(ViT-S/ViT-B/HiViT-B)および検出器(Faster RCNN, Oriented RCNN)と強く適合し、設定全体で一貫した利得をもたらす。
- アブレーション研究はデカップリングされたパラメータ予測とCAM統合の有効性を確認し、特定の順序(xy -> α -> wh)が最良の結果を生む。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。