[論文レビュー] Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Speech Robust Bench (SRB)を導入します。ASRの包括的な頑健性ベンチマークで、69の摂動を評価し、モデルを比較する指標を提供し、サブグループ別の公平性分析を含みます。
As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 114 input perturbations which simulate an heterogeneous range of corruptions that ASR models may encounter when deployed in the wild. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as the use of discrete representations, or self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females. Our results revealed noticeable disparities in the model's robustness across subgroups. We believe that SRB will significantly facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
研究の動機と目的
- 現実世界の劣化におけるASRモデルの頑健な評価を促進する。
- 非対立的および対抗的歪みを網羅する包括的な摂動バンクを定義する。
- ASR予測の有用性と安定性を測る指標(NWERとWERV)を提案する。
- オープンソースツールとデータセットを用いた標準化・拡張可能な頑健性評価を実現する。
提案手法
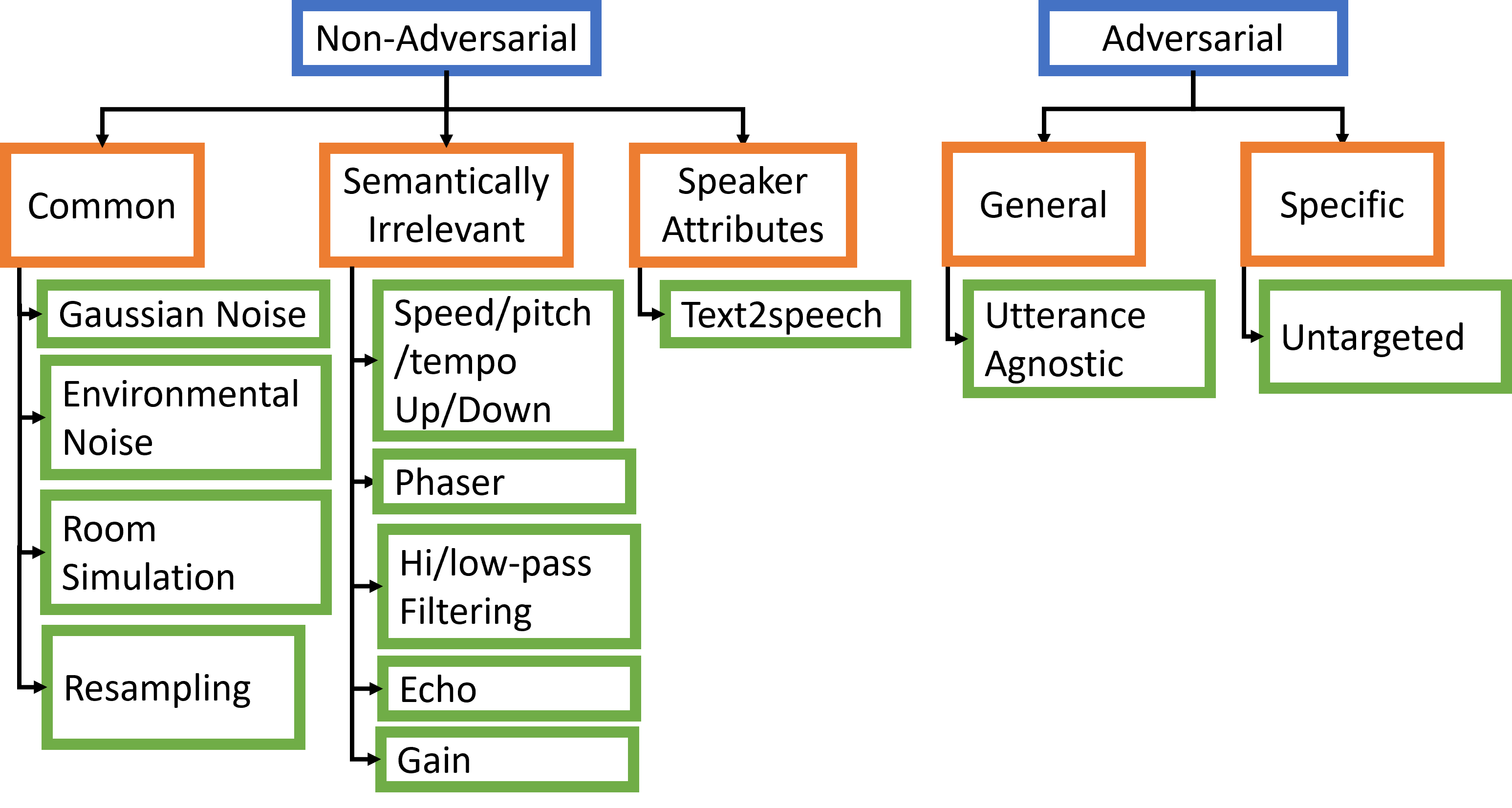
- 環境、話者関連、意味的、対抗的歪みを四段階の深さで網羅する摂動バンクを構築する。
- ターゲットASRモデルとベースラインモデルで摂動された音声を書き起こし、指標を算出する。
- 難易度を考慮して、ターゲットWERをベースラインWERで正規化してNormalized WER (NWER)を計算する。
- 複数の摂動サンプルに渡る予測の安定性を測るWER分散(WERV)を計算する。
- Librispeechを主要データセットとして使用し、多言語分析のためスペイン語サブセットデータを含める。
- オープンソースのSRBツールと摂動テストセットを提供し、即座に頑健性評価を可能にする。

実験結果
リサーチクエスチョン
- RQ1現在のASRモデルは、実世界の広範な摂動(非対立的および対抗的)に対してどれほど頑健ですか。
- RQ2モデルサイズ、アーキテクチャ、学習データは摂動全般における頑健性へどのように影響しますか。
- RQ3言語(英語対スペイン語)や性別などの人口サブグループ間で頑健性の特徴は異なりますか。
- RQ4SRBはサブグループ間のASR頑健性における公正性やバイアスのギャップを明らかにできますか。
主な発見
| 言語 | モデル | データ (h) | パラメータ数 (M) | WER |
|---|---|---|---|---|
| EN | wav2vec2-large-960h-lv60-self (w2v2-lg-slf) | 60,000 | 317 | 1.8 |
| EN | wav2vec2-large-robust-ft-libri-960h (w2v2-lg-rob) | 63,000 | 317 | 2.6 |
| EN | hubert-large-ls960-ft (hubt-lg) | 60,000 | 300 | 2.1 |
| EN | wav2vec2-base-960h (w2v2-bs) | 960 | 95 | 4.9 |
| EN | whisper-tiny.en (wsp-tn.en) | 680,000 | 39 | 6.4 |
| EN | deepspeech (ds) | 960 | 86 | 17.7 |
| ES | wav2vec2-large-xlsr-53-spanish (w2v2-lg-es) | 54,350 | 315 | 6.8 |
| ES | wav2vec2-base-10k-voxpopuli-ft-es (w2v2-bs-es) | 10,116 | 94 | 25.7 |
| Multi | whisper-large-v2 (wsp-lg) | 680,000 | 1,550 | 3.9/5.8 |
| Multi | whisper-tiny (wsp-tn) | 680,000 | 39 | 8.2/23.3 |
| Multi | mms-1b-fl102 (mms) | 55,000 | 964 | 15.4/15.7 |
- 大規模なモデルは平均的に頑健性が高い傾向があるが、特定の手法で訓練された小規模モデルが特定の摂動で性能を上回ることがある。
- Whisper large および Wav2Vec2.0 large バリアントは一般に高い頑健性を示すが、いくつかの摂動は小型モデルを優遇する(例:RIR、リサンプリング、テンポ低下)。
- 対抗的摂動はモデル間で異なる頑健性プロファイルを示す。あるモデルは発話に依存しない攻撃に強く、別のモデルは一般的な攻撃により効果的に耐える。
- スペイン語(非英語)の頑健性は多くのモデルで英語に遅れ、多言語モデルはスペイン語データでしばしば頑健性が低い。
- 性別による頑健性の差が存在し、女性話者は複数のモデルで一般的に難しく、この差は特定の摂動や対抗的攻撃の下で拡大する。
- SRBは詳細な公平性分析を可能にし、言語や人口統計サブグループによって頑健性が異なる条件を明らかにする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。