[論文レビュー] Speech2Vec: A Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
この論文では、音声のトランスクリプションを経由せずに、生の音声から直接意味的単語埋め込みを学習する、RNNに基づくエンコーダ・デコーダフレームワークであるSpeech2Vecを提案する。Word2Vecのスキップグラムおよびコンtinuous bag-of-words(CBOW)の目的関数を音声に適応させることで、テキストに欠落しているプロソディックおよび意味的手がかりを捉え、13の語類似度ベンチマークでテキストベースのWord2Vecを上回り、特に50次元の埋め込みで顕著な成果を示した。
In this paper, we propose a novel deep neural network architecture, Speech2Vec, for learning fixed-length vector representations of audio segments excised from a speech corpus, where the vectors contain semantic information pertaining to the underlying spoken words, and are close to other vectors in the embedding space if their corresponding underlying spoken words are semantically similar. The proposed model can be viewed as a speech version of Word2Vec. Its design is based on a RNN Encoder-Decoder framework, and borrows the methodology of skipgrams or continuous bag-of-words for training. Learning word embeddings directly from speech enables Speech2Vec to make use of the semantic information carried by speech that does not exist in plain text. The learned word embeddings are evaluated and analyzed on 13 widely used word similarity benchmarks, and outperform word embeddings learned by Word2Vec from the transcriptions.
研究の動機と目的
- テキストのトランスクリプションに依存せずに、生の音声から意味的単語埋め込みを学習する手法を開発すること。
- 自動音声認識(ASR)ベースの単語埋め込みパイプラインの限界、たとえばトランスクリプションの誤りやプロソディック情報の損失を克服すること。
- Word2Vecの成功を音声に拡張し、そのスキップグラムおよびコンtinuous bag-of-wordsの学習目的関数を音声系列に適応させること。
- 音声から得られる埋め込みが、テキストベースの対応物よりも豊かな意味的情報を捉えられるかどうかを評価すること。
- 学習済み埋め込みの安定性とばらつきが、異なる語の頻度および学習設定においてどのように変化するかを分析すること。
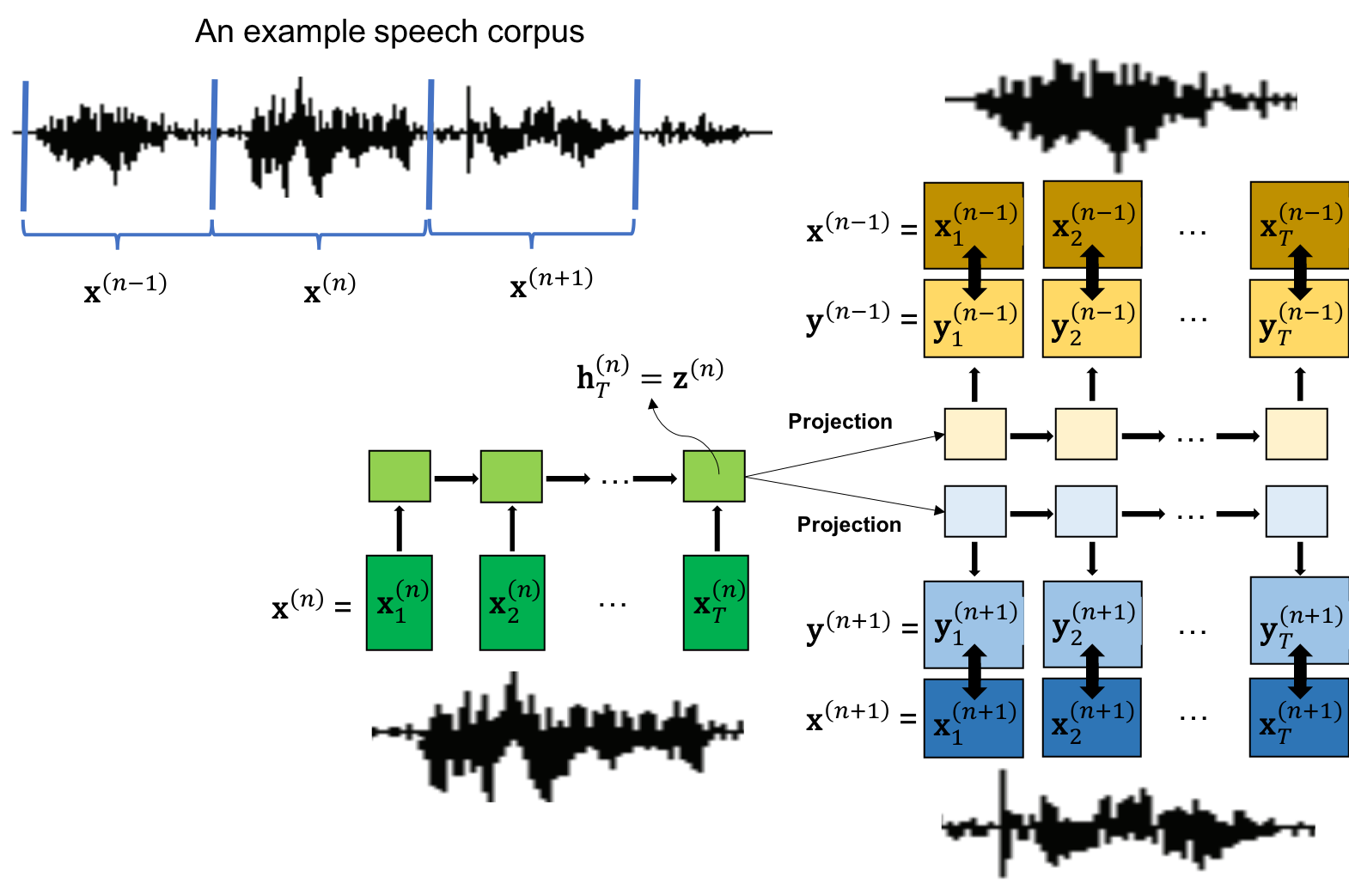
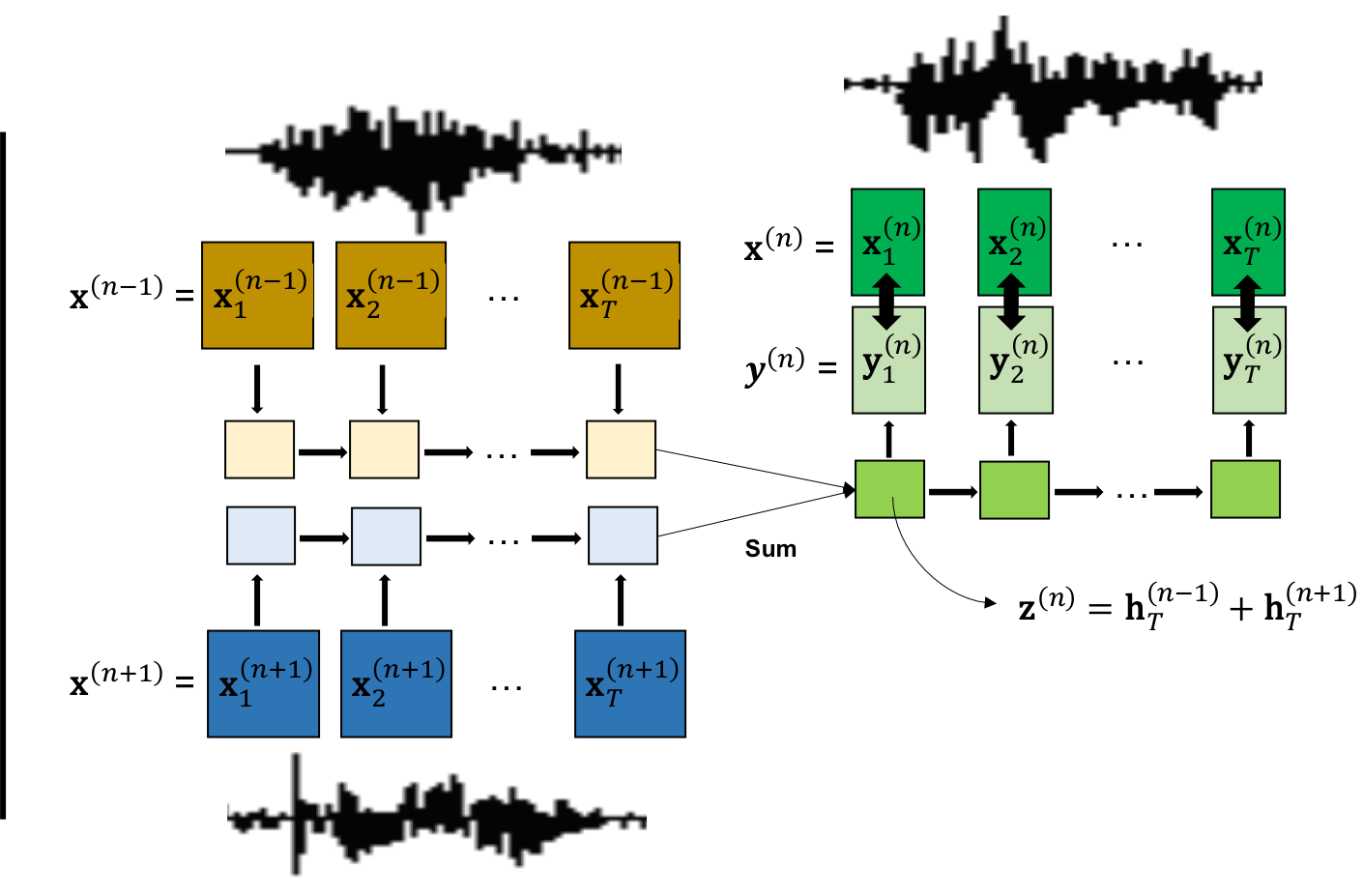
提案手法
- Speech2Vecは、可変長の音声系列(例:MFCC)を固定長の埋め込みにマッピングする、双方向RNNエンコーダ・デコーダフレームワークを用いる。
- モデルは、スキップグラムまたはコンtinuous bag-of-words(CBOW)の目的関数を用いて学習され、ターゲット語のセグメントの文脈がその埋め込みから予測される。
- スキップグラムの場合、エンコーダがターゲット語セグメントを処理し、デコーダが周囲の文脈セグメントを予測する。CBOWの場合、エンコーダが複数の文脈セグメントを符号化してターゲットを予測する。
- 音声セグメントは固定長にパディングされ、語レベルの境界を取得するために強制アラインメントが用いられ、教師ありセグメンテーションが可能になる。
- モデルはクロスエントロピー損失を用いてエンドツーエンドに学習され、正しい文脈セグメントを予測する尤度を最大化するように最適化される。
- 単語埋め込みはエンコーダの最終隠れ状態から導出され、語類似度ベンチマークを用いて評価される。
実験結果
リサーチクエスチョン
- RQ1テキストのトランスクリプションを経由せずに、生の音声から意味的単語埋め込みを学習できる、シーケンス・ツー・シーケンスRNNフレームワークは存在するか?
- RQ2プロソディック・ヒントを含む音声から学習することで、トランスクリプトされたテキストから学習するのと比較して、より優れた意味的表現が得られるか?
- RQ3スキップグラムとCBOWの両方のバリアントが、異なる語の頻度レベルにおいて性能と安定性でどのように比較されるか?
- RQ4語のトレーニングコーパス内での出現回数が増えるにつれて、単語埋め込みの分散はどのように変化するか?
- RQ5学習済み埋め込みが、類義語や対義語のような意味的関係をどの程度捉えられるか?
主な発見
- スキップグラムのSpeech2Vecは、13の語類似度ベンチマークのうち8つで、CBOWのSpeech2VecおよびテキストベースのWord2Vecを上回り、音声からの意味的表現学習の優位性を示した。
- 50次元の埋め込みを用いたSpeech2Vecが、大多数のベンチマークで最高のパフォーマンスを示し、生の音声から学習する際には、より小さな埋め込みサイズでも十分であることが示された。
- Speech2Vecの性能は、トレーニングコーパスのサイズが大きくなるにつれて顕著に向上し、10%から全データに増加した際の向上が顕著に見られた。
- スキップグラムのSpeech2Vecでは、語の頻度が高くなるにつれて、単語埋め込みの分散が低くなる傾向が見られ、高頻度語に対してより安定した性能と耐性があることが示唆された。
- t-SNEの可視化により、学習済み埋め込みが意味的構造を捉えていることが確認され、対義語(肯定的/否定的語)が空間的に分離され、類義語がまとまっていることが観察された。
- モデルが音声に内在するプロソディックおよび文脈的手がかりを捉える能力のおかげで、トランスクリプトを入力として用いても、テキストベースのWord2Vecよりも優れた意味的一般化が達成された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。