[論文レビュー] SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks
SpeechPrompt v2 は学習可能な語彙化器を用いたプロンプトチューニングを用いて、最小の学習可能パラメータで幅広い音声分類タスクを実行し、複数言語・タスクにおいて競合的または最先端の結果を達成します。
Prompt tuning is a technology that tunes a small set of parameters to steer a pre-trained language model (LM) to directly generate the output for downstream tasks. Recently, prompt tuning has demonstrated its storage and computation efficiency in both natural language processing (NLP) and speech processing fields. These advantages have also revealed prompt tuning as a candidate approach to serving pre-trained LM for multiple tasks in a unified manner. For speech processing, SpeechPrompt shows its high parameter efficiency and competitive performance on a few speech classification tasks. However, whether SpeechPrompt is capable of serving a large number of tasks is unanswered. In this work, we propose SpeechPrompt v2, a prompt tuning framework capable of performing a wide variety of speech classification tasks, covering multiple languages and prosody-related tasks. The experiment result shows that SpeechPrompt v2 achieves performance on par with prior works with less than 0.15M trainable parameters in a unified framework.
研究の動機と目的
- パラメータ効率が高く統一された音声分類を prompting によって必要性を動機づける。
- コンテンツとプロソディタスクおよび複数言語に跨るプロンプトフレームワークを開発する。
- 競争力のある性能を維持しつつ学習パラメータを削減する。
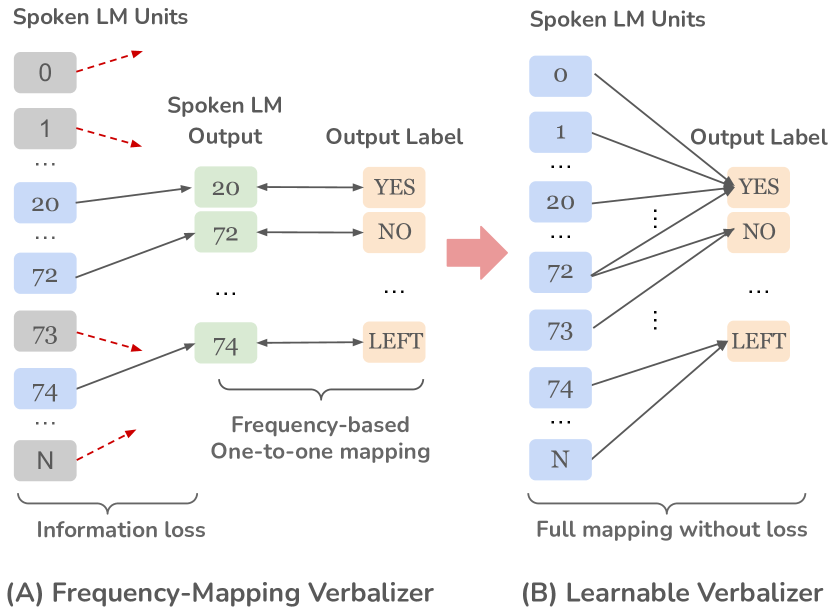
- LM 出力をタスクラベルへマッピングする能力を向上させる学習可能な語彙化器を導入する。
- 広範なタスクスイートにわたる一般化と制約を評価する。
提案手法
- 固定済みの事前学習済み音声言語モデル(GSLM および pGSLM)をバックボーンとして用い、パラメータを凍結する。
- 入力埋め込みと連結され、Transformer層の深い prompting に使用される小さなタスク特有のプロンプトベクトルを学習する。
- 学習可能な語彙化器(線形モデル)を適用して LM 出力分布をタスクラベルへ写像し、プロンプトと共に jointly trained。
- タスク固有のハイパーパラメータ調整は行わない;固定プロンプト長さ(l=5)とプロンプトサイズは約0.128Mパラメータ。
- 複数言語と音声特性を跨ぐ14データセットの10の音声分類タスクを評価。
- 完全に監視済み学習と事前学習/微調整パラダイムと比較。
実験結果
リサーチクエスチョン
- RQ1SpeechPrompt v2 は学習可能なパラメータを最小限に抑えつつ、幅広い音声分類タスクで競合的な性能を達成できるか?
- RQ2学習可能な語彙化器は音声LMにおける prompting の性能を一貫して改善するか?
- RQ3SpeechPrompt v2 はコンテンツ関連タスクとプロソディ関連タスク、そして言語間でどのように性能が異なるか?
- RQ4非英語や多様な音声データセットにおけるプロンプトチューニングの制約と安定性の懸念は何か?
主な発見
| タスク | 指標 | データセット | 言語 | クラス数 | SOTA(トップライン) | GSLM | GSLM+ | pGSLM | pGSLM+ |
|---|---|---|---|---|---|---|---|---|---|
| SCR | ACC (↑) | Google SC v1 | En | 12 | 98.6 [10] | 94.5 | 94.6 | 94.3 | 94.7 (-3.9) |
| Grabo SC | ACC (↑) | Google SC v1? | Du | 36 | 98.9 [11] | 92.4 | 92.7 (-6.2) | 17.5 | 19.6 |
| Lithuanian SC | ACC (↑) | Lithuanian SC | Lt | 15 | 91.8 [9] | 93.2 | 95.5 (+3.7) | 90.9 | 79.5 |
| Arabic SC | ACC (↑) | Arabic SC | Ar | 16 | 98.9 [9] | 99.7 | 100.0 (+1.1) | 85.6 | 92.6 |
| IC | ACC (↑) | Fluent SC | En | 24 | 99.7 [12] | 97.2 | 97.3 | 98.1 | 98.2 (-1.5) |
| LID | ACC (↑) | Voxforge | En, Es, Fr De, Ru, It | 6 | 99.8 [13] | 90.9 | 94.2 (-5.6) | 81.8 | 80.4 |
| FSD | EER (↓) | ASVspoof | En | 2 | 2.5 [13] | 18.5 | 13.5 | 13.1 (+10.6) | 18.3 |
| ER | ACC (↑) | IEMOCAP | En | 4 | 79.2 [13] | 42.1 | 44.3 | 49.9 | 50.2 (-29) |
| AcC | ACC (↑) | AccentDB | En | 9 | 99.5 [14] | 78.9 | 83.4 | 86.5 | 87.1 (-12.4) |
| SD | F1 (↑) | MUStARD | En | 2 | 64.6 [15] | 55.0 | 77.8 | 74.4 | 78.7 (+13.1) |
| GI D | F1 (↑) | VoxCeleb1 | En | 2 | 98.3 [17] | 86.2 | 87.3 | 91.6 (-6.7) | 86.2 |
| VAD | ACC (↑) | Google SC v2 & Freesound | En | 2 | 98.8 [18] | 96.6 | 96.9 | 98.3 (-0.5) | 98.1 |
| AuC | ACC (↑) | ESC-50 | ✖ | 50 | 97.0 [19] | 9.0 | 37.5 (-59.5) | 20.3 | 27.0 |
- SpeechPrompt v2 は競合的な性能を発現し、いくつかのタスクで最先端の結果を達成する(例:リトアニア語 SCR、アラビア語 SCR、Sarcasm Detection)。
- フレームワークは高いパラメータ効率を有し、タスクごとに学習可能な spoken-LM パラメータは0.1%未満(約0.15M)である。
- 学習可能な語彙化器は多くのタスクで GSLM の性能を改善し、一般にユニット-to-ラベルのマッピングの SHAP 分析による説明性向上にも寄与する。
- プロンプト調整は不安定性と性能のばらつきを生じることがあり、特に非英語や高度に多様な音声データでは未実施の per-task ハイパーパラメータ最適化が行われていない。
- プロンプトを用いた推論は統一された単純化されたパイプラインを実現し、広範な音声分類タスク群でSOTAに近づくまたは追従することが可能だが、一部のタスクは完全監視学習や事前学習/微調整法に遅れをとる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。