[論文レビュー] SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
本論文は SpeechTokenizer を提案する。統一された RVQ-based の音声トークナイザーで、意味情報と音響トークンを semantic distillation により統合し、Unified Speech Language Model (USLM) を構築し、再構成性能、SLMTokBench の性能、およびベースラインに対するゼロショット TTS の向上を示す。
Current speech large language models build upon discrete speech representations, which can be categorized into semantic tokens and acoustic tokens. However, existing speech tokens are not specifically designed for speech language modeling. To assess the suitability of speech tokens for building speech language models, we established the first benchmark, SLMTokBench. Our results indicate that neither semantic nor acoustic tokens are ideal for this purpose. Therefore, we propose SpeechTokenizer, a unified speech tokenizer for speech large language models. SpeechTokenizer adopts the Encoder-Decoder architecture with residual vector quantization (RVQ). Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Furthermore, We construct a Unified Speech Language Model (USLM) leveraging SpeechTokenizer. Experiments show that SpeechTokenizer performs comparably to EnCodec in speech reconstruction and demonstrates strong performance on the SLMTokBench benchmark. Also, USLM outperforms VALL-E in zero-shot Text-to-Speech tasks. Code and models are available at https://github.com/ZhangXInFD/SpeechTokenizer/.
研究の動機と目的
- テキストと一致する離散的な音声表現の必要性を、音声情報を完全に保持しつつ動機づける。
- 既存の semantic トークンタイプと acoustic トークンタイプを評価し、音声言語モデル構築における限界を特定する。
- RVQ 層全体で content と paralinguistic 情報を分離する unified tokenizer (SpeechTokenizer) を提案する。
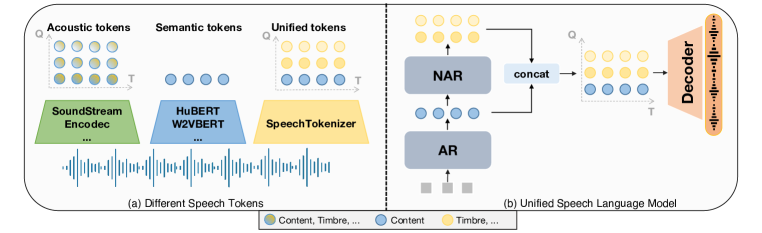
- SpeechTokenizer を活用した autoregressive および non-autoregressive 世代を実現する Unified Speech Language Model (USLM) を開発する。
- 競争力のある音声再構成、強力な SLMTokBench 性能、およびベースラインと比較したゼロショット TTS の改善を実証する。
提案手法
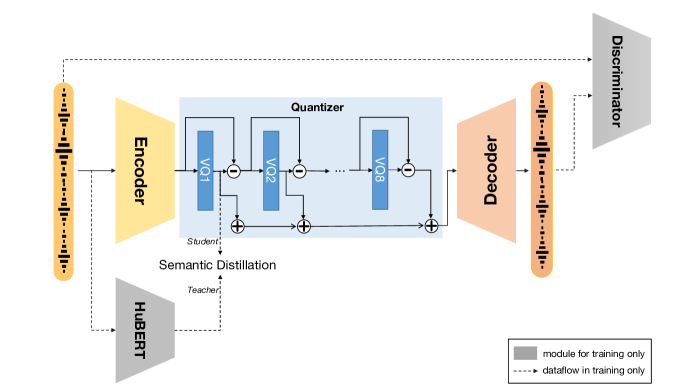
- EnCodec に似た時系列ダウンサンプリングを伴う Encoder-Decoder RVQ-GAN フレームワークを使用する。
- 最初の RVQ 層が semantic teacher (HuBERT) による continuous および pseudo-label distillation を介して導かれる semantic distillation を導入する。
- 再構成 GAN 目的関数と RVQ コミットメントおよび semantic distillation 損失を組み合わせて訓練する。
- 情報を階層的に RVQ 層間で分離させ、最初の層が content を捉え、後続の層が paralinguistic 詳細を符号化する。
- Unified Speech Language Model (AR on first-layer tokens; NAR on subsequent layers) を構築し、ゼロショット TTS の訓練を行う。
- SLMTokBench を通じた text alignment と情報保持を評価し、ゼロショット TTS および one-shot voice conversion を評価する。
実験結果
リサーチクエスチョン
- RQ1 unified SpeechTokenizer が semantic または acoustic トークンだけの場合よりも text alignment と音声情報保持の両方を改善できるか?
- RQ2 semantic ガイダンスを伴う階層的 RVQ トークン化は content モデリングと高品質な音声再構成を促進するか?
- RQ3 得られた USLM はゼロショットの text-to-speech で既存システムを上回り、content の正確さを維持または向上させるか?
- RQ4 semantic teacher の選択(例: HuBERT L9 対 averages または units) は下流の text alignment と再構成にどのような影響を与えるか?
- RQ5 RVQ 層間での information disentanglement が one-shot voice conversion のようなタスクにおいてどのような役割を果たすか?
主な発見
- SpeechTokenizer は EnCodec に匹敵する音声再構成能力を示し、WER を低減できる可能性があり、 content の保持能力が強いことを示唆する。
- SLMTokBench では SpeechTokenizer トークンが text mutual information を改善し、 baseline と比較して content の保持が競争力のあるまたは優れていることを示し、後段の RVQ 層は timbre の保持を強化する。
- ゼロショット TTS では SpeechTokenizer を用いた Unified Speech Language Model が VALL-E より低い WER と高い話者類似性を達成する。
- USLM はゼロショット TTS において話者類似性が優れ、MOS/SMOS スコアも競争力があり、 content と話者情報の効果的なデカップリングを示している。
- one-shot voice conversion 実験では後段の RVQ 層の情報が話者特性を符号化し、 VC の性能を制御可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。