[論文レビュー] SphereFace2: Binary Classification is All You Need for Deep Face Recognition
SphereFace2 はソフトマックスベースの多クラス学習を、 hypersphere 上のバイナリのワン・対・全(one-vs-all)フレームワークに置き換え、オープンセット顔認識を改善し、複数のベンチマークで最先端の結果を達成する。
State-of-the-art deep face recognition methods are mostly trained with a softmax-based multi-class classification framework. Despite being popular and effective, these methods still have a few shortcomings that limit empirical performance. In this paper, we start by identifying the discrepancy between training and evaluation in the existing multi-class classification framework and then discuss the potential limitations caused by the "competitive" nature of softmax normalization. Motivated by these limitations, we propose a novel binary classification training framework, termed SphereFace2. In contrast to existing methods, SphereFace2 circumvents the softmax normalization, as well as the corresponding closed-set assumption. This effectively bridges the gap between training and evaluation, enabling the representations to be improved individually by each binary classification task. Besides designing a specific well-performing loss function, we summarize a few general principles for this "one-vs-all" binary classification framework so that it can outperform current competitive methods. Our experiments on popular benchmarks demonstrate that SphereFace2 can consistently outperform state-of-the-art deep face recognition methods. The code has been made publicly available.
研究の動機と目的
- オープンセット顔認識におけるソフトマックスベースの多クラス学習の制限を識別する。
- ハイパースフィア上のバイナリ一対全(one-vs-all)学習フレームワークを提案する(SphereFace2)。
- 実用的な要素(バランス、イージー/ハード・マイニング、角度マージン、類似度調整)を組み込んだ原理的な損失を導出する。
- 標準的な FR ベンチマークにおいて性能と頑健性の向上を示す。
- 大規模なアイデンティティ集合に対するマルチGPU訓練のスケーラビリティの利点を示す。
提案手法
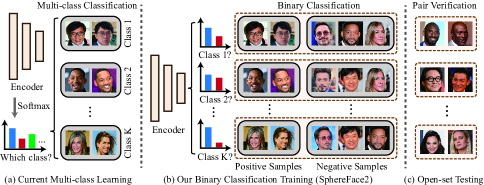
- 識別子ごとに1つのバイナリ分類器(K個)を構築し、対象クラスのデータを正例、その他を負例とする(ワン・バイ・オール)。
- 特徴ベクトルと分類器を正規化して単位ハイパースフィア上で二値分類を実行し、xとW_iのコサイン類似度を用いる。
- チューニング可能なバランスλ、角度マージン m_p および m_n、訓練の安定化のためのバイアス b を組み合わせた損失 L を提案する。
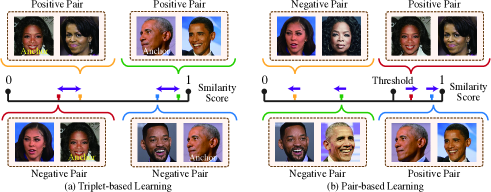
- 類似度調整 g(cos θ) = 2((cos θ + 1)/2)^t − 1 を導入し、類似度分布を広げて正例/負例の重なりを減らす。
- 角度マージン(m_p, m_n を用いた双方向)と任意のバイアスを組み込み、普遍的な判定境界を維持し、最終的に単一の形で表される L を得る。
- 正例/負例のバランス、難易度サンプルのマイニング、角度マージン、類似度調整の原理に基づく設計選択を、経験的検証やアブレーションとともに論じる。
- 分離されたバイナリ分類器による効率的なマルチ-GPU並列化を強調し、ソフトマックス正規化のオーバーヘッドを回避する。
実験結果
リサーチクエスチョン
- RQ1ハイパースフィア上のバイナリワン・バー・オール・フレームワークは、ソフトマックスベースの多クラスFR手法と同等以上を達成できるか?
- RQ2ソフトマックスのクローズドセットバイアスを取り除くことで、オープンセットの一般化能力とラベルノイズへの頑健性が向上するか?
- RQ3正例/負例のバランス、マイニング、角度マージン、類似度調整といった損失設計原理のうち、どれがバイナリFR性能を最も改善するか?
- RQ4SphereFace2 は大規模なアイデンティティ集合に対してマルチ-GPU訓練でどのようにスケールするか?
- RQ5標準的なFRベンチマークにおいて、SphereFace2 は最先端の損失と比較してどのような実証的利得を達成するか?
主な発見
| 損失関数 | LFW | AgeDB-30 | CA-LFW | CP-LFW | Combined |
|---|---|---|---|---|---|
| Softmax Loss | 98.20 | 87.23 | 88.17 | 84.85 | 89.05 |
| Coco Loss | 99.16 | 90.23 | 91.47 | 89.53 | 92.4 |
| SphereFace | 99.55 | 92.88 | 92.55 | 90.90 | 93.75 |
| CosFace | 99.51 | 92.98 | 92.83 | 91.03 | 93.89 |
| ArcFace | 99.47 | 91.97 | 92.47 | 90.85 | 93.97 |
| Circle Loss | 99.48 | 92.23 | 92.90 | 91.17 | 93.78 |
| CurricularFace | 99.53 | 92.47 | 92.90 | 90.65 | 93.70 |
| SphereFace2 | 99.50 | 93.68 | 93.47 | 91.07 | 94.28 |
- SphereFace2 は標準ベンチマークで、最先端のソフトマックスベース損失よりも一貫して検証精度を高く達成する。
- アブレーションにより、正例/負例のバランス、難易度サンプルのマイニング、角度マージン、類似度調整のそれぞれが性能向上に寄与することが示された。
- 全要素(λ、r、m、t)を含む最終損失は、最良の総合スコアをもたらし、例: 表2の結合検証で94.28%など。
- 二値化・プロキシベースのペアワイズ訓練により、ソフトマックスのクロス通信オーバーヘッドなしに、GPU間で自然な並列化が可能となる。
- 類似度調整済みコサイン mappings は類似度のダイナミックレンジを広げ、正例/負例の重なりを減らし、一般化を向上させる。
- SphereFace2 は大規模ベンチマーク(IJB-B、IJB-C、MegaFace)で強力な性能を示し、競争力のある TAR/TPIR 指標を達成している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。