[論文レビュー] Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data
Gen-FedSD は事前学習済みの Stable Diffusion モデルを用いてクライアント固有の合成データを生成し、ローカル FL データを IID に近づけ、非 IID 分布下で性能と収束を改善する。
The proliferation of edge devices has brought Federated Learning (FL) to the forefront as a promising paradigm for decentralized and collaborative model training while preserving the privacy of clients' data. However, FL struggles with a significant performance reduction and poor convergence when confronted with Non-Independent and Identically Distributed (Non-IID) data distributions among participating clients. While previous efforts, such as client drift mitigation and advanced server-side model fusion techniques, have shown some success in addressing this challenge, they often overlook the root cause of the performance reduction - the absence of identical data accurately mirroring the global data distribution among clients. In this paper, we introduce Gen-FedSD, a novel approach that harnesses the powerful capability of state-of-the-art text-to-image foundation models to bridge the significant Non-IID performance gaps in FL. In Gen-FedSD, each client constructs textual prompts for each class label and leverages an off-the-shelf state-of-the-art pre-trained Stable Diffusion model to synthesize high-quality data samples. The generated synthetic data is tailored to each client's unique local data gaps and distribution disparities, effectively making the final augmented local data IID. Through extensive experimentation, we demonstrate that Gen-FedSD achieves state-of-the-art performance and significant communication cost savings across various datasets and Non-IID settings.
研究の動機と目的
- 非 IID データ分布の下で、プライバシーを保護する分散型トレーニングパラダイムとしてフェデレーテッドラーニングを動機づける。
- 合成データ生成を通じて各クライアントのデータ分布をグローバル分布と合わせることで、FLの性能低下の根本原因に対処する。
- 各クライアントのデータ不足 gaps に合わせて高品質なクラス条件付き画像を合成する Gen-FedSD を提案する。
- 各クライアントごとの拡散モデルデータ拡張がIIDに近いローカルデータを生み出し、標準データセット上のFLベンチマークを改善することを示す。)
提案手法
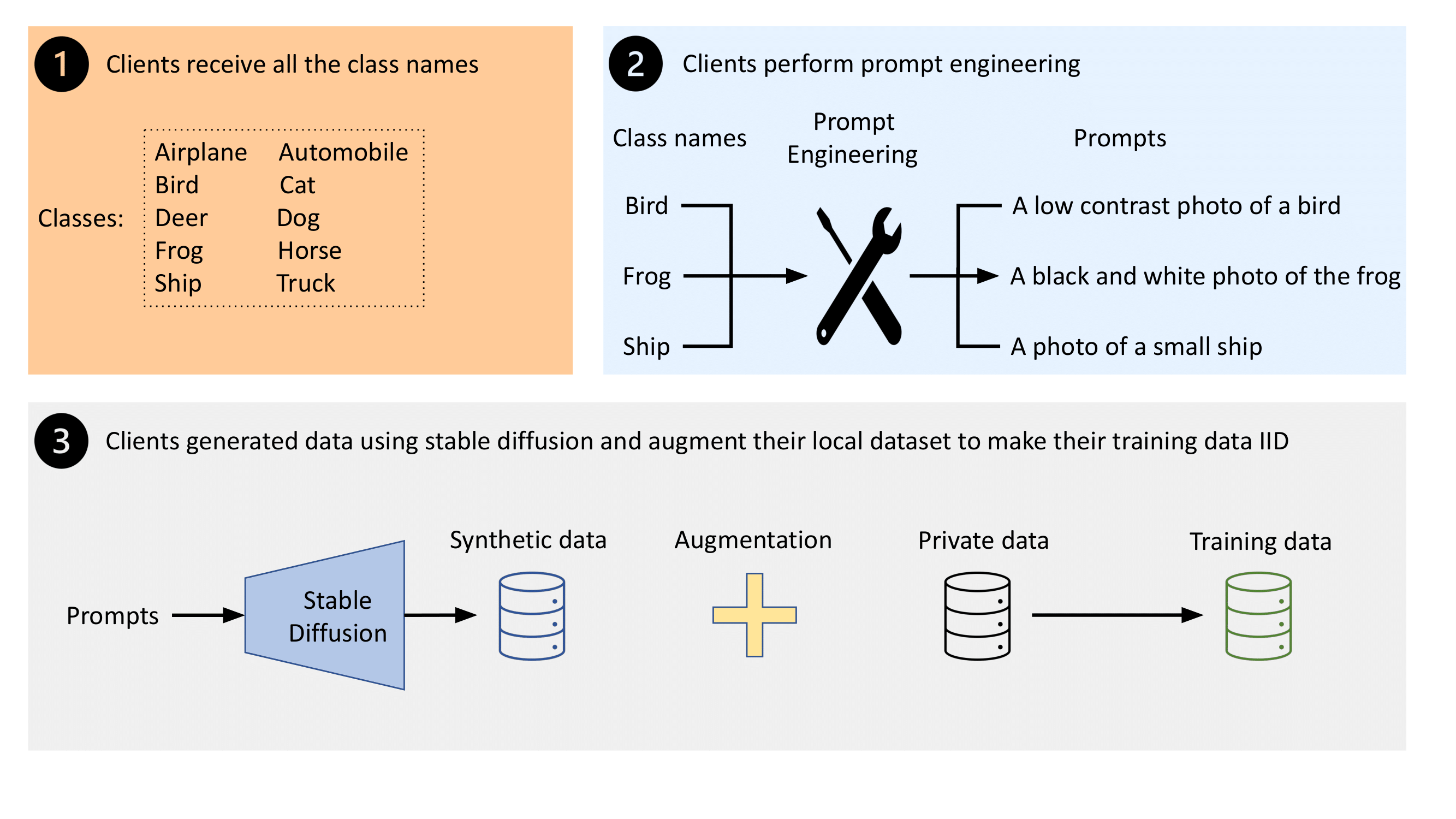
- クライアントはサーバーからグローバルなクラスラベルを受け取り、各クラスを記述するテキストプロンプトを生成する。
- プロンプトからクラス条件付き画像を合成するために事前学習済み Stable Diffusion モデルを使用する。
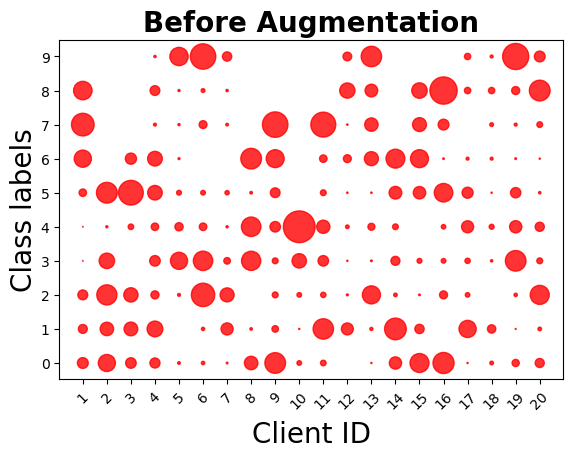
- 各クライアントごとにクラスごとのカウントを均等化するように合成データを生成し、グローバル分布に対してIIDとなる拡張されたローカルデータセットを得る。
- 拡張データをローカルデータと結合しFLモデルの訓練に用いてクライアントドリフトを低減する。
- パフォーマンスへのプロンプト多様性の影響を調べるため、標準プロンプトと多様なプロンプトの設計を評価する。
- 標準的なFLベースライン(FedAvg、FedProx、FedNova、Scaffold)とGen-FedSDを比較する。
実験結果
リサーチクエスチョン
- RQ1各クライアントの拡散ベースのデータ拡張は、ローカルクライアント分布をグローバルデータ分布に合わせて非IID効果を緩和できるか?
- RQ2プロンプト設計(多様なプロンプト vs 固定プロンプト)は合成データの品質とFLの性能にどう影響するか?
- RQ3さまざまな非IID設定下で CIFAR-10 および CIFAR-100 における Gen-FedSD の精度向上と通信コストの影響はどの程度か?
- RQ4Gen-FedSD は拡散モデルのデバイス上推論を可能にしつつプライバシーを保護するか?
主な発見
- Gen-FedSD は非IID設定下でFLベースラインの精度を大幅に向上させる(例:軽度の不均一性下で CIFAR-10 で少なくとも 12%、CIFAR-100 で 6%)。
- 極端な非IID性の下で、Gen-FedSD は少なくとも 20%(CIFAR-10)および 7%(CIFAR-100)の精度向上をもたらす。
- Gen-FedSD は収束を加速し、評価データセット全体で通信コストを削減する。
- 固定プロンプトと比較して、プロンプトの多様性は Gen-FedSD の性能をさらに高める。
- Gen-FedSD はいくつかのベースラインの性能を改善し、拡張が適用されるとときに FedAvg を上回ることもある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。