[論文レビュー] Stable LM 2 1.6B Technical Report
Stable LM 2 1.6B は、1.6B パラメータを持つオープンなデコーダー専用言語モデルで、透明性のある多言語データ混合で訓練され、量子化およびエッジデバイスのスループット機能とともに公開され、微調整と評価結果が提供されます。
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
研究の動機と目的
- Stable LM 2 1.6B を構築するために用いられたデータ収集と訓練手順を説明する。
- 事前学習のアーキテクチャ、トークナイザー、最適化設定を説明する。
- 会話能力を向上させるために用いられたファインチューニング、アライメント、自己知識訓練手法の詳細を説明する。
- few-shot(少数ショット)および多言語、そして多ターン対話ベンチマークを対象とした包括的評価を提示する。
- 提供と公開:エッジデバイスや他の推論フレームワーク向けの量子化済みチェックポイントを含む。
提案手法
- FlashAttention-2 を用いた 4096 トークンのコンテキストを持つ 1.6B デコーダー専用 Transformer を訓練し、混合精度を適用する。
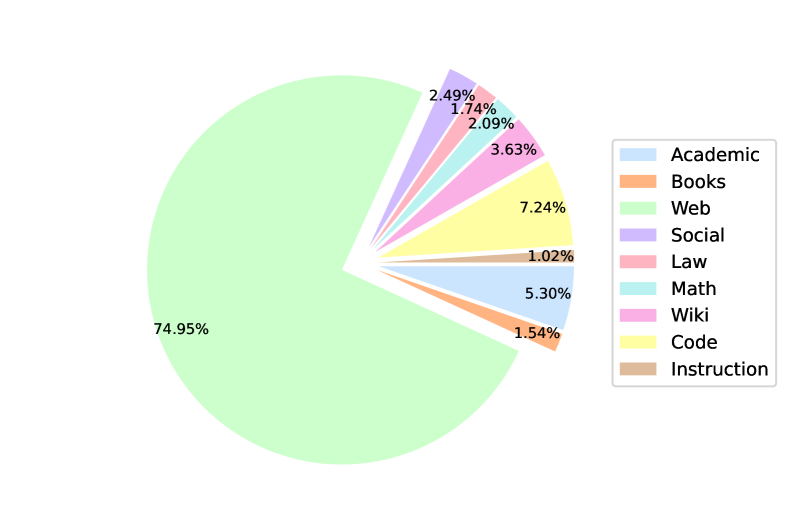
- ドメインと言語の明示的なサンプリングウェイトを用いた約 2 兆トークンの多言語データ混合を使用する(Table 1)。
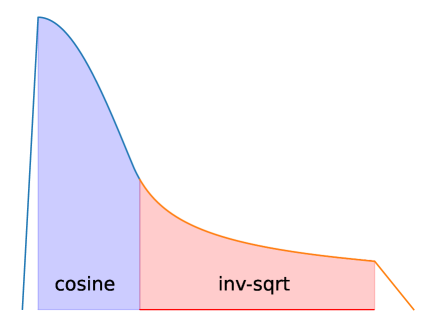
- ウォームアップ、コサインおよび rsqrt 減衰を組み合わせた多段階の学習率スケジュールを適用し、その後リニアクールドダウンを行う。
- Hugging Face Hub の指示データセットによる教師付きファインチューニングを実施し、その後 Direct Preference Optimization および self-knowledge training loop を行う。
- さまざまな推論フレームワーク向けに Q4_0、Q4_1、Q5_K_M GGUF、および INT4 形式の量子化チェックポイントを提供・公開する。
実験結果
リサーチクエスチョン
- RQ1Stable LM 2 1.6B は、同程度のサイズの他のベースモデルを複数の英語ベンチマークで上回り、会話設定において MT-Bench の大規模モデルに近づく。
- RQ2モデルは、英語以外の評価設定でドイツ語、スペイン語、フランス語、イタリア語、ポルトガル語、オランダ語において強力な多言語能力を示す。
- RQ3指示微調整バリアント(stablelm-2-1_6b-dpo)は Phi-1.5 を上回り、いくつかの指標で Phi-2 と比較して好ましい。
- RQ4量子化済みチェックポイント(Q4_0、Q4_1、Q5_K_M GGUF、INT4)が提供され、オンデバイスまたはフレームワーク特有のデプロイを効率化する。
- RQ5エッジデバイスで低精度を使用する際のスループット測定は大幅な利得を示し、様々なフレームワークの図が示されている。
主な発見
- Stable LM 2 1.6B は、同程度のサイズの他のベースモデルを複数の英語ベンチマークで上回り、会話設定において MT-Bench の大規模モデルに近づく。
- モデルは、英語以外の評価設定でドイツ語、スペイン語、フランス語、イタリア語、ポルトガル語、オランダ語において強力な多言語能力を示す。
- 指示微調整バリアント(stablelm-2-1_6b-dpo)は Phi-1.5 を上回り、いくつかの指標で Phi-2 と比較して好ましい。
- 量子化済みチェックポイント(Q4_0、Q4_1、Q5_K_M GGUF、INT4)が提供され、オンデバイスまたはフレームワーク特有のデプロイを効率化する。
- エッジデバイスで低精度を使用する際のスループット測定は大幅な利得を示し、様々なフレームワークの図が示されている。
- 訓練には約 92,000 GPU-時間を要し、推定カーボンフットプリントは 11 tCO2eq である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。