[論文レビュー] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
論文は Stable Video Diffusion (SVD) を提示し、 curated 大規模ビデオデータセット上で三段階のデータ戦略を用いて訓練された潜在動画拡散モデルにより、最先端のテキスト-to-動画および画像-to-動画合成を実現し、強力なモーションおよびマルチビューの priors を持つことを示す。
We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .
研究の動機と目的
- 大規模なビデオ拡散事前学習のための効果的なデータキュレーション戦略を特定する。
- ビデオ LDM のための三段階の訓練体系(画像前学習、動画前学習、高品質ファインチューニング)を提案し検証する。
- 厳選された前学習が強力なモーション表現を生み出し、テキスト-to-動画、画像-to-動画、マルチビュー生成を含む下流タスクに利益をもたらすことを示す。
- ベースモデルが堅牢なモーション priors を提供し、効率的にさまざまなタスクへファインチューニングできること(例:カメラモーションのための LoRA)を示す。
提案手法
- 時系列レイヤを挿入した潜在動画拡散モデルを、事前学習済みの画像拡散バックボーンに組み込んで使用する。
- カット検出、合成キャプション、オプティカルフローフィルタリング、OCR、CLIPベースの美学と類似度指標を含む体系的なデータキュレーションワークフローを開発する。
- 三段階で訓練する:(i)2D拡散モデルでの画像前学習、(ii)低解像度での大規模動画前学習、(iii)小規模データセットでの高解像度での高品質ファインチューニング。
- EDM のノイズスケジュールをより高いノイズ値へシフトさせ、高解像度のファインチューニングを改善する。
- フレームレートでのマイクロコンディショニングおよびカメラモーション用の LoRA モジュールによるモーション制御を有効にする。
- 学習したモーション priors を活用して一貫したマルチビュー出力を作成するためにマルチビュー データセットでファインチューニングを実証し、マルチビュー生成をデモンストレーションする。
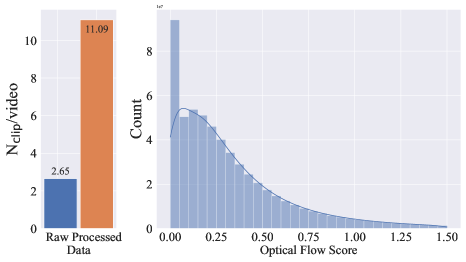
実験結果
リサーチクエスチョン
- RQ1大規模なビデオコーパスの慎重なデータキュレーションは、ファインチューニング後の最終的なビデオモデルの性能を向上させるか。
- RQ2三段階の訓練体系が高品質なテキスト-to-動画および画像-to-動画合成に与える影響は。
- RQ3ベースのビデオモデルは強力なモーション表現と下流タスクの使用可能な3D/マルチビュー priors を提供できるか。
- RQ4 curated data で事前学習したビデオ拡散モデルは、品質と効率の点で最先端のマルチビュー/合成法と比較してどうか。
主な発見
- 厳選されたビデオデータでの事前学習は、高品質なファインチューニング後も顕著な性能向上をもたらす。
- 厳選データで事前学習したベースモデルは強力なゼロショットのテキスト-to-動画性能を達成し、UCF-101 のいくつかのベースラインを上回る。
- 高品質データでのファインチューニングは、クローズドソースモデルに対しても高解像度のテキスト-to-動画および画像-to-動画の結果で競争力を持つ。
- ベースモデルは強力なモーション表現を提供し、下流のマルチビュー生成の priors として機能し、Zero123XL や SyncDreamer などのマルチビュー手法を上回る。
- LoRA モジュールを使用することで、画像-to-動画生成における明示的なカメラモーション制御が可能になる。
- 三段階の訓練戦略は大規模データセット(約600M サンプル)へ効果的にスケールし、限定的な計算資源でマルチビュー微調整を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。