[論文レビュー] Statler: State-Maintaining Language Models for Embodied Reasoning
Statler は、対になった世界状態リーダーとライターLLMが明示的に推定世界状態を維持・更新し、具現化されたロボット計画を導くフレームワークを導入し、仮想および実 robots で長期目標タスクにおいて Code-as-Policies より強い利得を達成する。
There has been a significant research interest in employing large language models to empower intelligent robots with complex reasoning. Existing work focuses on harnessing their abilities to reason about the histories of their actions and observations. In this paper, we explore a new dimension in which large language models may benefit robotics planning. In particular, we propose Statler, a framework in which large language models are prompted to maintain an estimate of the world state, which are often unobservable, and track its transition as new actions are taken. Our framework then conditions each action on the estimate of the current world state. Despite being conceptually simple, our Statler framework significantly outperforms strong competing methods (e.g., Code-as-Policies) on several robot planning tasks. Additionally, it has the potential advantage of scaling up to more challenging long-horizon planning tasks.
研究の動機と目的
- LLMs による世界状態を明示的に維持することで長期ロボット計画を動機付け・実現する。
- 現在の状態を条件付ける世界状態リーダーとライターを用いたモデルベースのアプローチを開発する。
- シミュレーションの卓上領域と実ロボットでの状態維持の頑健性とスケーラビリティを実証する。
提案手法
- クエリと現在の状態に基づいて実行可能な動作を生成する世界状態リーダーと、動作実行後に状態を更新する世界状態ライターという二つの専門化LLMをプロンプトする。
- 外部のJSON形式の世界状態表現を維持し、ステップ間で読み取り・更新して潜在的ダイナミクスを追跡する。
- デモンストレーションを用いてリーダー/ライターのプロンプトを訓練または誘導する;統合型と分割リーダー/ライター構成を比較することもある。
- 複数の卓上操作タスクを横断して、Statler を CaP と CaP with Chain-of-Thought プロンプトと比較評価する。
- 別々のリーダー/ライターコンポーネントと異なる状態維持戦略の寄与を示すアブレーションを示す。
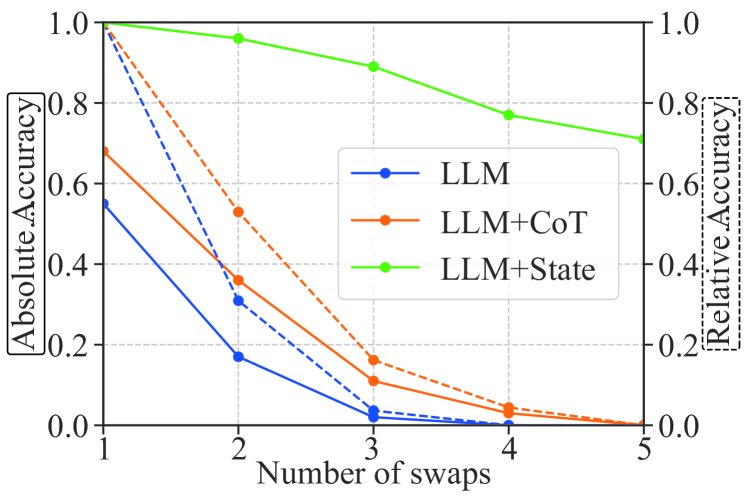
実験結果
リサーチクエスチョン
- RQ1明示的に維持された世界状態は、状態を持たないポリシーと比較して多段階的なロボット計画を改善するか。
- RQ2長期的なタスクにおいて、別個の世界状態リーダーとライターLLMは統合プロンプトに比べて測定可能な利点を提供するか。
- RQ3過去の相互作用を推論する際に、シミュレーション領域と実ロボット実験で Statler の性能はどのように異なるか。
- RQ4状態維持アブレーションがタスク成功率と各ステップの正確さに与える影響はどの程度か。
主な発見
| Method | Episode success rate (Pick & Place) | Episode success rate (Disinfection) | Episode success rate (Weight) |
|---|---|---|---|
| CaP | 0.00 (0.54) | 0.00 (0.68) | 0.00 (0.84) |
| CaP+CoT | 0.25 (0.76) | 0.00 (0.20) | 0.30 (0.88) |
| Statler (ours) | 0.50 (0.88) | 0.40 (0.82) | 0.55 (0.93) |
- Statlerは、シミュレーションのピック&プレース、消毒、重量推論タスクでCaPおよびCaP+CoTを大きく上回る。
- 非時間的クエリはCaPにとってほぼ完璧だが、時間的クエリではCaP が崩壊する;Statler は記憶ベースの質問で高い性能を維持する。
- 実ロボット実験では、Statler はCaPよりエピソード成功率とステップ成功率が高く、LLM推論が主な失敗要因となる(知覚/操作も寄与)。
- アブレーションにより、別個の世界状態リーダーとライターを維持することが統合モデルよりも高い性能を示し、エピソード完了には状態維持が不可欠であることが示された。
- Statler は領域を越えて頑健性を示し、長期的な計画タスクへのスケーラビリティも約束する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。