QUICK REVIEW
[論文レビュー] Stochastic Answer Networks for Natural Language Inference
Xiaodong Liu, Kevin Duh|arXiv (Cornell University)|Apr 21, 2018
Topic Modeling参考文献 24被引用数 51
ひとこと要約
本論文は自然言語推論(NLI)の多段推論を行うStochastic Answer Networks (SAN)を紹介し、通過ごとに隠れ状態を洗練させ、SNLI、MultiNLI、SciTail、Quora Question Pairs で最先端の結果を達成します。
ABSTRACT
We propose a stochastic answer network (SAN) to explore multi-step inference strategies in Natural Language Inference. Rather than directly predicting the results given the inputs, the model maintains a state and iteratively refines its predictions. Our experiments show that SAN achieves the state-of-the-art results on three benchmarks: Stanford Natural Language Inference (SNLI) dataset, MultiGenre Natural Language Inference (MultiNLI) dataset and Quora Question Pairs dataset.
研究の動機と目的
- 自然言語推論 (NLI) のための多段・反復推論を、単一ステップ予測を超えて動機づける。
- Stochastic Answer Network (SAN) アーキテクチャを提案し、推論ステップ全体で状態を維持・更新する。
- SAN が単一ステップのベースラインを上回り、複数のベンチマークで最先端の結果を達成することを示す。
- 推論ステップ数と確率的予測ドロップアウトの影響をロバスト性と分析する。
提案手法
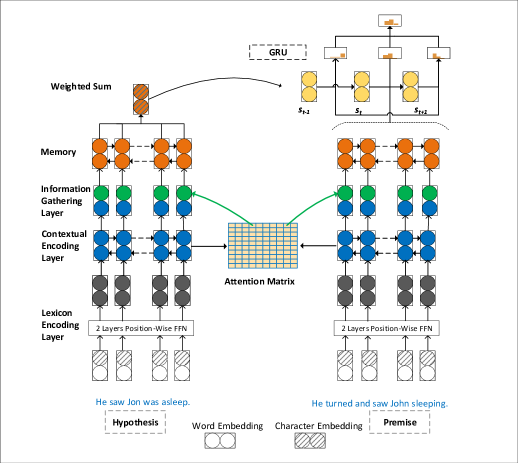
- 四層の SAN アーキテクチャ: 辞書エンコード、文脈エンコード、メモリ生成、反復的な回答モジュール。
- Lexicon 層は語彙と文字エンベディングを連結して E^p および E^h を premise と hypothesis に対して形成する。
- Contextual encoding 層は maxout を用いた2つの BiLSTM 層で C^p および C^h を生成する。
- Memory 層は内積アテンションと BiLSTMs を用いて作業メモリ M^p および M^h を生成する。
- Answer モジュールは GRU で s_t の多段状態更新を行い、ステップごとの予測 P_t^r を導出し、それらを平均して最終的な P^r を得る。
- Training は最終平均化段階で stochastic prediction dropout を用いてロバスト性を促進する。
実験結果
リサーチクエスチョン
- RQ1SAN の多段推論は単一段ベースラインより NLI を改善するか?
- RQ2SAN は標準的な NLI ベンチマーク(SNLI、MultiNLI、SciTail、Quora)でどう性能を示すか?
- RQ3SAN にとって最適な推論ステップ数 (T) はいくつで、性能にどう影響するか?
- RQ4確率的予測ドロップアウトを取り入れるとモデルのロバスト性と性能にどう影響するか?
- RQ5SAN アプローチは事前学習済み文脈埋め込みやマルチタスク学習と組み合わせた場合に一般化できるか?
主な発見
- SAN は四つのデータセット(SNLI、MultiNLI、SciTail、Quora)全てで単一ステップベースラインを一貫して上回る。
- SciTail では、SAN は単一ステップモデルより顕著なマージンで向上(dev で +3.89:85.46→89.35)。
- SAN は SciTail と Quora Question Pairs のテストセットで最先端の結果を達成し、SNLI と MultiNLI でも大規模な外部知識や事前学習埋め込みなしで競争力を維持している。
- 5段階の推論構成を使用すると SciTail dev および比較可能なベンチマークで最良の結果を得られ、一方でより多くのステップは一貫して性能を向上させなかった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。