[論文レビュー] Strategic Reasoning with Language Models
事前学習済み言語モデルは、検索・値の付与・信念追跡を構造化する体系的に生成されたプロンプトを用いることで、マトリックスゲームや交渉ゲームにおいて柔軟な戦略的推論を実行でき、新しいゲームや目的へfew-shotデモンストレーションで一般化できる。
Strategic reasoning enables agents to cooperate, communicate, and compete with other agents in diverse situations. Existing approaches to solving strategic games rely on extensive training, yielding strategies that do not generalize to new scenarios or games without retraining. Large Language Models (LLMs), with their ability to comprehend and generate complex, context-rich language, could prove powerful as tools for strategic gameplay. This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstrations of reasoning about states, values, and beliefs to prompt the model. Using extensive variations of simple matrix games, we show that strategies that are derived based on systematically generated prompts generalize almost perfectly to new game structures, alternate objectives, and hidden information. Additionally, we demonstrate our approach can lead to human-like negotiation strategies in realistic scenarios without any extra training or fine-tuning. Our results highlight the ability of LLMs, guided by systematic reasoning demonstrations, to adapt and excel in diverse strategic scenarios.
研究の動機と目的
- AIエージェントの新しい戦略的状況での一般化ギャップを動機づけ、対応する。
- LLMsに戦略的計画能力を付与するプロンプトベースの手法を提案する。
- few-shotデモンストレーションを通じて、新規ゲーム構造・目的・部分情報へ一般化を可能にする。
- 現実的なシナリオで再訓練なしに人間のような交渉行動を示す。
提案手法
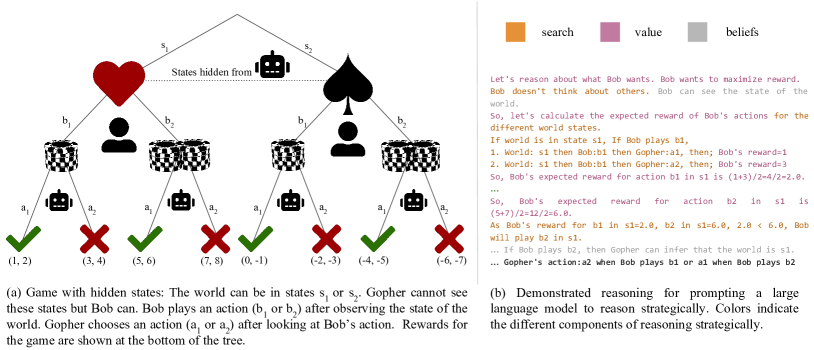
- 戦略的推論のデモンストレーション(探索、値の付与、信念追跡)を自動生成するプロンプトコンパイラを開発。
- 行動選択前のチェーンオブソート推論プロンプトを用いて、文脈内デモンストレーションでLLMへバイアスをかける。
- マトリックスゲームでは、報酬・プレイヤー・可観測性・ターンを変えて一般化を検証。
- 交渉ゲームでは、人間のデモンストレーションを注釈付けして、値と信念を推論するモデルを指導。
- 大規模な意思決定空間と複雑な推論を文脈内制限内で管理するためにツール(探索と計算)を組み込む。
- 複数のLLM(code-davinci-002および複数のテキストモデル)を用いて、ベースラインやablationsと比較評価する。
実験結果
リサーチクエスチョン
- RQ1LLMsは体系的に生成されたプロンプトを用いて新しいゲーム構造や目的へ戦略的推論を一般化できるか。
- RQ2推論を探索・値の付与・信念追跡へ分解することは、従来のプロンプトより信頼性を向上させるか。
- RQ3LLMsは追加の訓練なしに現実的な設定で人間と交渉し、人間のような振る舞いを示せるか。
- RQ4部分的可観測性と情報の変動は、モデルの戦略的推論と信念形成にどのような影響を与えるか。
主な発見
- 探索・値の付与・信念追跡を構造化するプロンプトは、新しいペイオフとゲーム構造へ一般化を可能にする。
- 因数分解された推論は、新規ゲーム構造と部分情報への一般化をほぼ完璧に達成し、ベースラインプロンプトやablationsを上回る。
- このアプローチは、再訓練なしで現実性と質の面で人間に近い交渉行動を支援する。
- デモンストレーションを用いたゼロショットで、新しい目的(例:福利の最大化やカスタムダキシティ指標)へ適応可能。
- 反復的推論は交渉の公正性指標を改善し、Deal or No Dealのシナリオで信念形成のないモデルを上回る。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。