[論文レビュー] Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
SPIRES は、柔軟なスキーマ駆動のプロンプティング手法を用いたゼロショット学習により、ネストされた知識を抽出・ grounding して知識ベースを構築するオープンソースの OntoGPT 実装と強力な grounding 性能を提供します。訓練データなしで新しいタスクを可能にし、識別子 grounding に ontologies を活用します。
Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
研究の動機と目的
- 自然言語テキストからタスク固有の訓練データなしに、複雑でネストされた知識スキーマを自動的に埋めることを可能にする。
- LLMs を用いたプロンプトベースの抽出を活用しつつ、外部オントロジーから恒久的な識別子へエンティティを grounding する。
- ネストされた属性構造に対応し、推論のための OWL への変換をサポートする、柔軟なスキーマ駆動フレームワークを提供する。
- SPIRES を複数のドメインで示し、 grounding 精度をベースラインの LLM プ Prompt と比較する。
提案手法
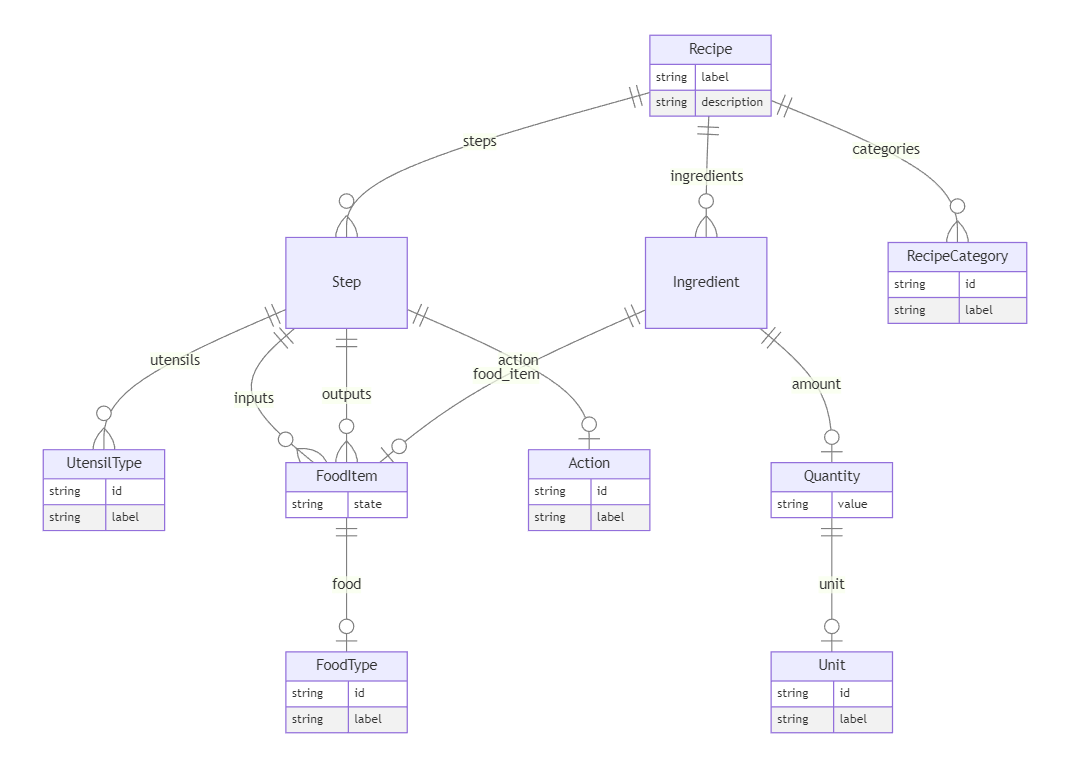
- 知識スキーマ S を、属性と値域を含むクラスの集合として定義する。マルチ値属性とネストされた inline クラスを含む。
- S、ターゲットクラス C、および入力テキスト T から、疑似 YAML 属性テンプレートと TextIntro ブロックを用いて構造化プロンプト p を生成する。
- LLM にプロンプトを完成させてもらい、構造化形式の応答 r を得る。
- r を解析して、S に適合するインスタンス i を再帰的に埋め、葉のエンティティをオントロジー(例:FOODON、Wikidata)やツール(Gilda、OGER)を用いて識別子へ grounding する。
- 任意で、埋め込まれたインスタンスを OWL に翻訳し、OWL ツール(ROBOT、Elk)で推論を行う。
- LinkML によるスキーマ定義と grounding のための OAKlib を用い、複数ドメインの事前作成済みスキーマを提供する OntoGPT ベースの Python 実装を提供する。
実験結果
リサーチクエスチョン
- RQ1SPIRES は、訓練データなしで未構造のテキストから任意にネストされた知識スキーマを埋めることができるか?
- RQ2SPIRES は、 grounding を用いずっぱりのプロンプトと比較して恒久的なオントロジー識別子へのエンティティ grounding をどの程度改善するか?
- RQ3MeSH/オントロジーへ grounding した場合、確立された生物医学的関係抽出タスクで SPIRES の性能はどの程度良いか?
- RQ4レシピ、シグナル伝達経路、疾病治療など多様なドメインで SPIRES の実用性と精度はどの程度か?
主な発見
- SPIRES は grounding 精度が高く、例:GPT-3.5-turbo で GO ターム grounding が 100 件中 98 件、GPT-4-turbo で 100 件中 97 件。
- SPIRES を用いない GPT-3.5-turbo は GO タームの正しい識別子をほぼゼロに近い値で生成することが多く、 grounding がない場合の大量のハルシネーションを示した。
- EMAPA オントロジーでは、GPT-3.5-turbo で全 100 タームに対して正しい識別子を得たのに対し、GPT-4-turbo は一部のオントロジーに対する grounding を継続的に拒否した。
- BioCreative Chemical-Disease Relation タスクでは、chunking 付きの SPIRES が F=41.16(P=0.43、R=0.39)、no-chunking が F=36.64(P=0.63、R=0.26)を GPT-3.5-turbo で達成し、GPT-4-turbo は F=43.80(P=0.69、R=0.32)を達成した。
- GPT-3.5-turbo での SPIRES は BC5CDR で混成ながら競争力のある性能を示し、訓練データを使用した 18 チームの平均をやや下回る位置に、GPT-4-turbo は grounding の挙動が異なることを示した。
- grounding はプロンプトのみのアプローチより顕著に改善され、訓練データなしでのゼロショット、スキーマ駆動の KB 埋め込みの実現性を裏付ける。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。