[論文レビュー] Studying LLM Performance on Closed- and Open-source Data
tldr: 本論文は、OpenAI CodexスタイルのLLMsを用いて、オープンソースとMicrosoftの閉鎖ソースコードを比較し、C#およびC++でのコード補完、要約、生成を評価する。C#では差が小さいが、閉鎖ソースデータでのC++は顕著な劣化が見られる。Few-shot学習とBM25 retrieved exemplars はいくつかのギャップを緩和できる。
Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
研究の動機と目的
- OSSデータで訓練されたLLMsが、大手ソフトウェアベンダー(Microsoft)の商用・閉鎖ソースコードに適用した場合も同様の性能を発揮するかを評価する。
- OSSと閉鎖ソースデータセットを横断して、C#とC++を比較することで言語特有の差を評価する。
- 性能差の潜在的な原因を調査し、few-shotのin-context learningやretrievalベースのexemplarsがそれを埋められるか検討する。
- OSSのエグゼンプルがin-context learning技術を介して閉鎖ソースコードの性能を改善できるかを検討する。)
提案手法
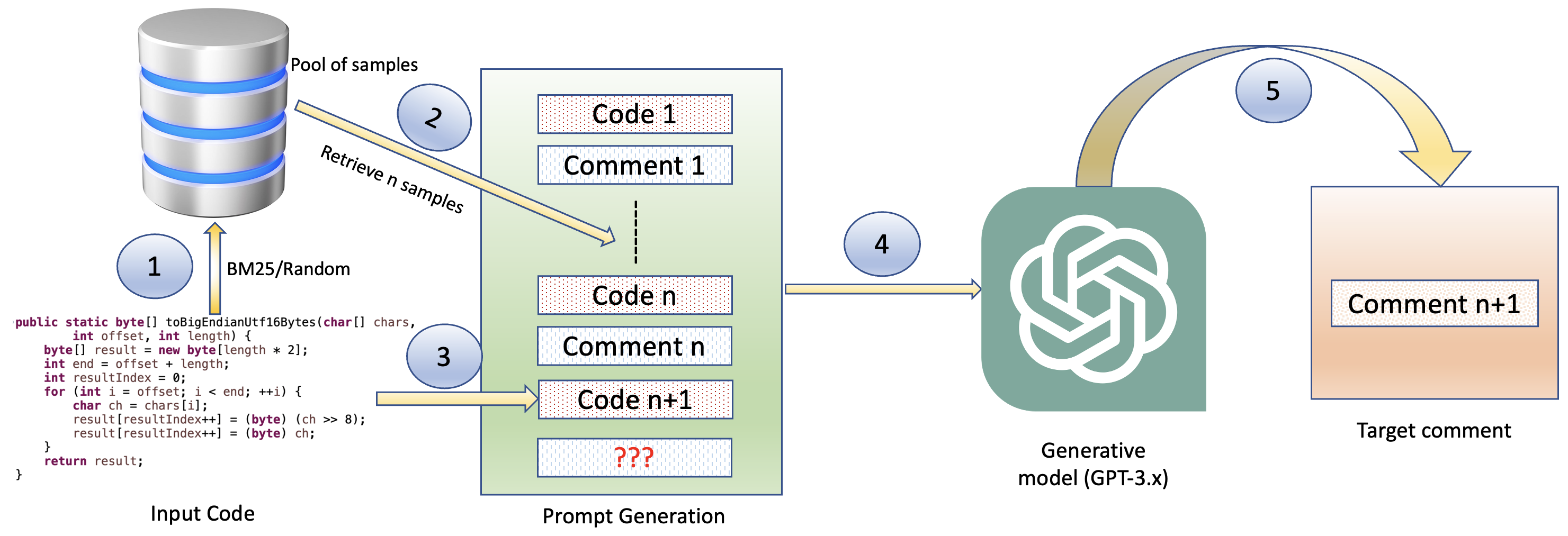
- ファインチューニングなしで、2つの市販LLM(Code-Davinci-002とGPT-3.5-Turbo)を使用。
- CodeXGLUEスイートの4つのタスクを評価する:Token Completion、Line Completion、Code Summarization、Code Generation。
- C#とC++について、OSSと閉鎖ソースの性能を比較する。
- CodeSummarizationとCodeGenerationのエグザンプルとして、ランダムに選択したサンプルとBM25で取得したサンプルをFew-shot学習として適用する。
- 評価指標として、Exact-Match、BLEUの派生、ROUGE-L、METEOR、Edit Similarity を用い、適用可能な場合は統計検定を報告する。
実験結果
リサーチクエスチョン
- RQ1RQ1: 学習言語とタスクを横断して、LLMsはオープンソースデータとクローズドソースデータで異なる性能を示すか?
- RQ2RQ2: オープンソースのエグザンプルを用いたfew-shot学習は、閉鎖ソースデータの性能を改善できるか?
- RQ3RQ3: OSSと閉鎖ソースデータで見られるC#とC++間の性能差の原因は何か?
主な発見
- For token completion, C# shows no significant OSS vs closed-source difference with Code-Davinci-002 (71.32% OSS vs 71.59% closed; p=0.67).
- For token completion in C++, there is a significant drop from OSS (71.93%) to closed-source (64.42%) with Code-Davinci-002 (p<0.01).
- Line completion exhibits the same language disparity: C# shows no significant OSS vs closed-source difference; C++ shows a significant drop in closed-source performance.
- Code summarization with few-shot learning and BM25-retrieved samples tends to reduce OSS vs closed-source gaps for C#, with BM25 providing some gains; for C++, gaps persist and can be amplified when BM25 is used, depending on the model.
- Code generation generally underperforms relative to summarization, with larger gaps for C++ between OSS and closed-source, even with few-shot learning.
- Overall, C# shows consistent performance across OSS/closed-source; C++ displays meaningful degradation on closed-source data, and BM25-retrieved few-shot samples can mitigate some, but not all, gaps.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。