[論文レビュー] Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4
要約: 本論文は、構造化プロンプトと心智理論推論を用いて専門的な訓練なしで不完全情報ゲームをプレイするGPT-4ベースのエージェント Suspicion-Agent を提案し、Leduc Hold’em で競争力のあるパフォーマンスと複数ゲームでの定性的成功を示す。
Unlike perfect information games, where all elements are known to every player, imperfect information games emulate the real-world complexities of decision-making under uncertain or incomplete information. GPT-4, the recent breakthrough in large language models (LLMs) trained on massive passive data, is notable for its knowledge retrieval and reasoning abilities. This paper delves into the applicability of GPT-4's learned knowledge for imperfect information games. To achieve this, we introduce extbf{Suspicion-Agent}, an innovative agent that leverages GPT-4's capabilities for performing in imperfect information games. With proper prompt engineering to achieve different functions, Suspicion-Agent based on GPT-4 demonstrates remarkable adaptability across a range of imperfect information card games. Importantly, GPT-4 displays a strong high-order theory of mind (ToM) capacity, meaning it can understand others and intentionally impact others' behavior. Leveraging this, we design a planning strategy that enables GPT-4 to competently play against different opponents, adapting its gameplay style as needed, while requiring only the game rules and descriptions of observations as input. In the experiments, we qualitatively showcase the capabilities of Suspicion-Agent across three different imperfect information games and then quantitatively evaluate it in Leduc Hold'em. The results show that Suspicion-Agent can potentially outperform traditional algorithms designed for imperfect information games, without any specialized training or examples. In order to encourage and foster deeper insights within the community, we make our game-related data publicly available.
研究の動機と目的
- 不特定のタスク訓練なしで不完全情報ゲームに対する事前学習済み大規模言語モデルの活用を動機づける。
- 観察の解釈、ルール理解、計画を可能にするモジュール型プロンプトベースのアーキテクチャを導入する。
- 心智理論(ToM)推論を取り入れて対戦相手の行動を予測し影響を与える。
- 複数のゲームにまたがる一般化を示し、従来の不完全情報アルゴリズムと比較する。
提案手法
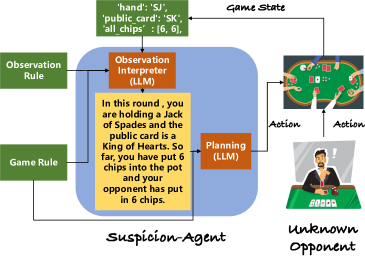
- ゲーム解法をモジュールに分解する:観察解釈器、ゲームルール理解、計画、反省、評価者。
- 低レベルのゲーム状態を自然言語記述に変換して GPT-4 に feed する。
- 歴史から学び計画を立てる通常の計画フローと反省を用いる。
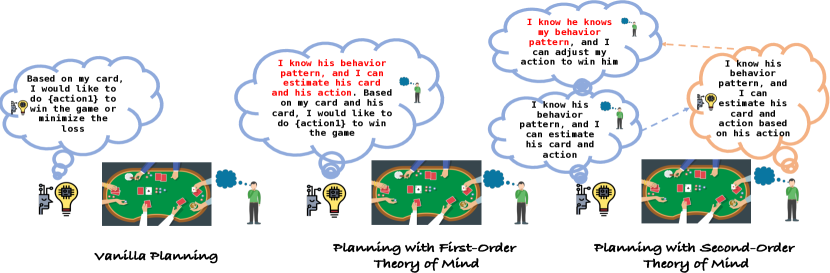
- 一阶および二阶の ToM 計画を導入して対戦相手の行動を予測し計画を適応させる。
- 対戦相手の手札強さと計画への反応を推定する ToM を用いた計画を実装する。
- 三つの二人対戦ゲームを定性的に評価し、Leduc Hold’em では CFR、NFSP、DMC、DQN に対して定量的に比較する。
実験結果
リサーチクエスチョン
- RQ1Suspicion-Agent は従来の不完全情報アルゴリズムと比べて特別な訓練なしで同等以上を達成できるか。
- RQ2ToM(第一秩序と第二秩序)は多様な対戦相手に対する性能にどのように影響するか。
- RQ3GPT-4 ベースのアプローチは Leduc Hold’em 以外の複数の不完全情報ゲームへ一般化できるか。
- RQ4対戦相手の観察と回顧を含めることは性能にどのような影響を与えるか。
- RQ5異なる ToM の順序は戦略的有効性の点でどう異なるか。
主な発見
- Suspicion-Agent(GPT-4) は提示された実験で Leduc Hold’em に特化して訓練されたベースラインを上回る。
- ToM 計画を備えた GPT-4 ベースのエージェントは、素の計画よりも CFR、DMC、NFSP など異なる対戦相手戦略への適応性が高い。
- 同じ設定で GPT-4 は GPT-3.5 よりも著しく上回り、GPT-3.5 は性能の低下を顕著に示す。
- 第二秩序 ToM 計画はより攻撃的で搾取的な戦略(例:ブラフ)を可能にし、ブラフ傾向の対戦相手に対するチップ獲得を高める。
- 定性的結果は、追加の訓練や例なしで Coup および Texas Hold’em Limit への一般化を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。