[論文レビュー] SVIT: Scaling up Visual Instruction Tuning
SVIT は視覚指示調整のための420万命令データセットを構築し、SVIT-v1.5 が新しいコアセットデータレシピと完全学習およびLoRA微調整の両方を用いて、複数のベンチマークで最先端のマルチモーダルLLMsを上回る。
Thanks to the emerging of foundation models, the large language and vision models are integrated to acquire the multimodal ability of visual captioning, question answering, etc. Although existing multimodal models present impressive performance of visual understanding and reasoning, their limits are still largely under-explored due to the scarcity of high-quality instruction tuning data. To push the limits of multimodal capability, we Scale up Visual Instruction Tuning (SVIT) by constructing a dataset of 4.2 million visual instruction tuning data including 1.6M conversation question-answer (QA) pairs, 1.6M complex reasoning QA pairs, 1.0M referring QA pairs and 106K detailed image descriptions. Besides the volume, the proposed dataset is also featured by the high quality and rich diversity, which is generated by prompting GPT-4 with the abundant manual annotations of images. We also propose a new data recipe to select subset with better diversity and balance, which evokes model's superior capabilities. Extensive experiments verify that SVIT-v1.5, trained on the proposed dataset, outperforms state-of-the-art Multimodal Large Language Models on popular benchmarks. The data and code are publicly available at https://github.com/BAAI-DCAI/Visual-Instruction-Tuning.
研究の動機と目的
- マルチモーダルモデルにおけるデータ不足を克服するため、視覚指示調整のスケーリングを推進する。
- GPT-4プロンプトを介して生成された、大規模で多様性が高く高品質な VG/COCO ベースの指示データセットを構築する。
- 多様性とバランスを考慮したコアセット選択を含むデータ優先のモデル戦略を提案する。
- 標準ベンチマーク上で SVIT-v1.5 が既存の MLLMs を上回ることを示す。
提案手法
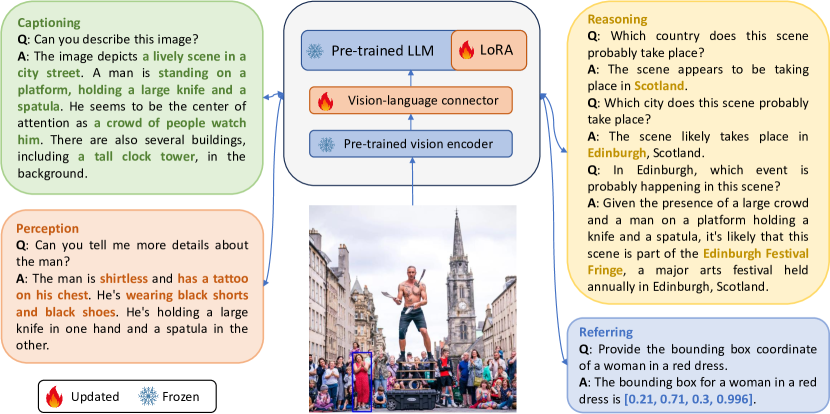
- 豊富な注釈と GPT-4 プロンプトを用いて Visual Genome と COCO から SVIT を構築し、4つのタスクタイプを生成する: 会話型 QA、複雑な推論 QA、 referring QA、詳細な画像説明。
- 2段階の学習パイプラインを用いる。 vision encoder と LLM を凍結したまま画像-テキストペアでビジョン-言語コネクタを事前学習し、その後、ビジュアル指示データでコネクタとLLM(フルまたは LoRA)を微調整する。
- GPT-4 主導の概念オーバーラップフィルタとYes/No バランス調整を介して、多様性とバランスを意識したコアセットとして SVIT-core-150K を導入する。
- 既存データの一部(例: LLaVA-Instruct-150K)を SVIT-core-150K に置換してデータ効率を評価し、より大きな効果を得るため SVIT-train へとスケールアップする。
実験結果
リサーチクエスチョン
- RQ1高品質な視覚指示データをスケールアップすることが、標準ベンチマーク全体でマルチモーダルモデルの性能にどう影響するか?
- RQ2多様性とバランスを意識したデータサブセット(コアセット)は、指示チューニングの効率と有効性を改善できるか?
- RQ3SVITデータで訓練した場合の全パラメータ微調整と LoRA 微調整の利得は何か?
- RQ4データサイズを増やす(SVIT-train)は、知覚と認知タスクの両方に一貫した改善をもたらすか?
主な発見
| Method | LLM | VQA-v2 | GQA | VisWiz | SQA_I | VQA_T | MME_P | MME_C | MMB | MMB_CN | SEED | MMMU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLIP-2 | Vicuna-13B | – | 41.0 | 19.6 | 61.0 | 42.5 | – | – | – | – | – | – |
| LLaVA-v1.5 (Full) | Vicuna-13B | 80.0 | 63.3 | 63.3 | 53.6 | 71.6 | 61.3 | 67.8 | 63.3 | 61.6 | 33.6 | – |
| SVIT-v1.5 (LoRA) | Vicuna-13B | 80.1 | 63.4 | 56.7 | 69.9 | 61.1 | 1560.3 | 364.3 | 68.3 | 63.2 | 61.8 | 34.1 |
| SVIT-v1.5 (Full) | Vicuna-13B | 80.3 | 64.1 | 56.4 | 70.0 | 60.8 | 1565.8 | 323.2 | 69.1 | 63.1 | 61.9 | 33.3 |
- SVIT-v1.5(Full)はほとんどのベンチマークで LLaVA-v1.5 および他のモデルを上回り、MMEの知覚と認知で顕著な向上を示す。
- SVIT-v1.5(LoRA)は MME の認知で LLaVA-v1.5(LoRA)を上回り、効率的な微調整で顕著な向上を示す。
- 多様性重視の SVIT-80K-D は、ランダムに選択した SVIT-80K と比較してパフォーマンスを 20.3 ポイント改善する。
- 学習データの Yes/No 問題をバランスさせた SVIT-80K-B は、SVIT-80K より MME で 7.1% の改善を達成。
- SVIT-train をスケールアップ(より大きなデータ)すると、SVIT-80K より総合 MME スコアが +12.7% 増加し、物体の存在、色、OCR タスクで顕著な改善を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。